



redis基础
1. 什么是redis?Redis题库 副本
- Redis是基于c语言编写的高性能的非关系型的内存数据库。
2. redis的优势和劣势?
- 优势:基于内存,io多路复用 所以读写快。丰富的数据类型,持久化机制,支持事务,支持主从复制。
3. 解释什么是IO多路复用?
- io多路复用是redis的网络模型。传统的客户端和服务器交互就是一个线程接受和处理。redis做了优化采用一个线程接受多个sorcket请求,然后经过队列分配给文件处理器处理。
4. redis的基本数据类型有哪些?
- string字符串:
- 基本命令get ,set,del,mset,mget
# 设置 key-value 类型的值> SET name lin
OK
# 根据 key 获得对应的 value
> GET name
"lin"# 判断某个 key 是否存在
> EXISTS name
(integer) 1# 返回 key 所储存的字符串值的长度
> STRLEN name
(integer) 3# 删除某个 key 对应的值
> DEL name
(integer) 1
- value最大为512m
- 使用场景:缓存对象,常规计数器(点赞和阅读量),分布式锁
- 常规计数器:因为redis是单线程的所有执行命令都是原子性的,所以利用incr key 0 ,incr key 1进行计算
# 设置 key-value 类型的值
> SET number 0
OK
# 将 key 中储存的数字值增一
> INCR number
(integer) 1# 将key中存储的数字值加 10
> INCRBY number 10(integer) 11# 将 key 中储存的数字值减一
> DECR number
(integer) 10# 将key中存储的数字值键 10
> DECRBY number 10(integer) 0
- 分布式锁:使用setnx key value实现。当key不存在时,将值设为value且返回1。当key存在了,就返回0。
- 共享session:分布式系统中,session存放在redis中,多个机器都可以拿到这一个session就可以避免重复登录。
- list(插入有序)
- 3.2之前为双向链表,之后为quickList
- 基本用法:
# 将一个或多个值value插入到key列表的表头(最左边),最后的值在最前面
LPUSH key value [value ...]
# 将一个或多个值value插入到key列表的表尾(最右边)
RPUSH key value [value ...]# 移除并返回key列表的头元素
LPOP key
# 移除并返回key列表的尾元素
RPOP key
# 返回列表key中指定区间内的元素,区间以偏移量start和stop指定,从0开始
LRANGE key start stop
# 从key列表表头弹出一个元素,没有就阻塞timeout秒,如果timeout=0则一直阻塞
BLPOP key [key ...] timeout# 从key列表表尾弹出一个元素,没有就阻塞timeout秒,如果timeout=0则一直阻塞
BRPOP key [key ...] timeout
- 使用场景:
- 轻量级的消息队列。stream也可以做消息队列(后期使用mq做业务时,可以结合发邮件给平台或者合作商,或者航变通知)
- Set 无需不可重复 哈希表 sadd key numer scard key 可以用做共同关注的好友,公众号
- zset 有序不可重复 zadd 有序是根据score计算每个元素的权重进行排序。 点赞排行榜。
- 增加一条用户为haoqiang 分数为80分 学科为数学的记录。
[图片]
- 增加一条用户为haoqiang 分数为80分 学科为数学的记录。
- Hash 哈希表 非常适合存储对象 比如退改库规则中的 退+出发机场+到达机场 航司 规则
存储一个哈希表uid:1的键值
HMSET uid:1 name Tom age 152
存储一个哈希表uid:2的键值
HMSET uid:2 name Jerry age 132
获取哈希表用户id为1中所有的键值
HGETALL uid:1
1) "name"
2) "Tom"
3) "age"
4) "15"
- 其他如stream流,位图等
5. 每种数据类型对应的使用场景?
- 分布式锁 redisson.lock 锁订单防止重复下单
- 消息队列 list和stream都可以实现轻量的消息队列。list实现原理:lpush或者rpush头插和尾插入链表。lpush key [vlaue value2 value3] 消费Blpop。生产订阅模式主要通过subscribe 和publish生产和消费
- 缓存
- 计数器(string 字符串为整数时) 原理:redis中的incr numer 自增加1; decr numer 每调用一次减一
- 限流器:限制流量,请求的频率。主要四种算法。
- 计数器算法 整数+时间戳。在时间范围内达到整数的阈值就禁止访问,过了时间重置。缺点就是会在时间临界出出现时间突刺。
- 滑动窗口算法 计算器算法的进化版解决时间突刺。 始终以当前时间划分窗口,在时间内达到阈值就禁止访问。
- 漏桶算法 思想:不管入口流量多大,通过漏桶算法,出口流量是均匀流出的,达到一个限流的作用。
- 令牌桶算法 为了满足满性能资源,采用令牌桶算法。思想 在一个桶均匀产生令牌,当桶满了就停止产生,然后请求进来必须先拿令牌才能获取资源。所以请求流量少,使用的令牌就少,当突发流量来时,能够以最大令牌数量去限制流量。相对而言是动态的。
- 秒杀
- 秒杀功能:在短时间内,几十上百万人抢夺某件商品的场景。主要出现的问题是
- 1.服务器能够抗住海量请求。
- 为了解决服务器压力问题。采用redis将抢和下单分开。也就是redis用于库存的加减,下单通过Kafka或者mq消息队列实现下单到数据库。
- 2.如何保证库存数量的正常下单,也就是禁止超卖,以及避免少卖。
- 超卖产生的原因:当第一步查询库存的时候,由于大量并发导致库存已经消耗完了,就会导致超卖。
- 超卖通过redis和lua脚本实现。具体通过lua脚本中写redis命令先查库存,再查用户购买数量,然后减库存,记录用户数据,这几步作为一个整体的原子性操作。
- 少卖问题产生的原因:当请求redis超时的时候,其实已经扣减库存成功,但超时就没有下单进来,导致少卖。或者给mq发送下单消息的时候丢失,也会导致少卖问题。可以采用将已经购买成功的用户信息保存到磁盘之后再慢慢mq入库。
- 3.保障购买者是用户而不是黄牛。限制ip和加验证码。
- 秒杀中的高并发问题 一台redis 6万/s的请求。如果100万请求进来,使用nginx做负载均衡调用20个redis实例即可。
6. redis做缓存用,那你知道有哪几种缓存模式吗?四种缓存模式
- 旁路缓存模式:
- 我们最常用的缓存模式。
- 特点:读数据时,直接读redis的缓存,不存在时再去访问数据库,返回数据的同时,将新数据更新到缓存中。写数据的时候,直接写到数据库中,并删除缓存中对于的旧数据。
- 由于写直接写到数据库,所以适合读多写少的场景
- 读穿缓存模式/写穿缓存模式:
- 模式与旁路缓存模式类似,最大的区别在于请求与redis之间加了一层服务,由服务决定查缓存还是数据库。
- 其次写入数据时,也就有多种策略。缓存中存在,则先更新缓存再入库。不存在是有两种 先入库后入缓存,和先缓存后入库。
- 好处是 代码更简洁。但是效率比旁路缓存慢
- 异步缓存写入模式
- 与写穿缓存模式的的最大区别,在于等一段时间才将数据一块写入的数据库中。
7. 在你的生产中你怎么使用的redis?(结合代码关键字)
- 用作mysql的缓存 人工设置机票调价和行李调价使用redis做缓存,用来支持搜索的并发请求。
- 分布式锁-下单的的时候锁订单(重复下单),幂等?
- 退改库中使用hash类型存储退改规则 大key:退+出发机场+到达机场 ,小key:航司 ,value 存放具体的退信息。
8. redis支持事务吗?用什么实现的,跟MySQL事务的区别?
- 支持简单事务,使用lua脚本实现的。区别在于redis不支持事务的回滚。redis的事务类似mysql的串行化。
9. 如何保证redis和mysql的一致性?
- 先讲有哪些解决方案,然后结合项目说一下。
- 没有完美的方案,也不可能实现完美的一致性,所以走思想,结合义务去选择。
第一种,比如我们更新数据到mysql之后,不操作redis等过期时间到了,再从mysql中获取数据到redis。
- 优点是,简单,不需要额外的操作redis。缺点就是 不一致性时间较长,容易读到脏数据,对于过期时间的设置也需要挑战性。
第二种 使用过期时间兜底,然后更新mysql之后,同时将redis的旧数据删除(更新不建议采取,因为更新有时序性问题,数据有误)。相对第一种一致性更强一些,但是缺点就是需要额外操作redis且删除操作容易失败。
- 更新存在的问题:无论是「先更新数据库,再更新缓存」,还是「先更新缓存,再更新数据库」,这两个方案都存在并发问题,当两个请求并发更新同一条数据的时候,可能会出现缓存和数据库中的数据不一致的现象。
- 如果对缓存的命中率要求较高,可以采用先更新数据库,再更新缓存,使用分布式锁解决并发产生的不一致问题。
- 删除缓存和数据库优先存在的问题:
- 先删除缓存,再更新数据库,在「读 + 写」并发的时候,还是会出现缓存和数据库的数据不一致的问题。
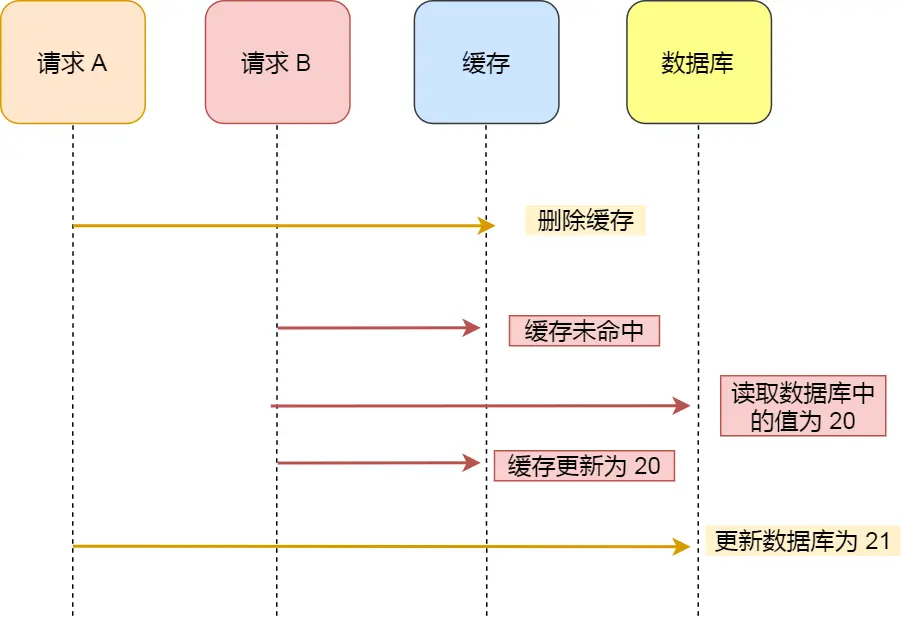
- 前提:先更新数据库,后删除缓存,再加过期时间兜底。
但如果删除操作失败了呢?https://blog.csdn.net/x_xhuashui/article/details/129657086- 使用消息队列来异步地删除或更新缓存,避免阻塞主线程或者丢失消息。
- 使用消息队列异步重试缓存的情况是指,当信息发生变化时,先更新数据库,然后删缓存,如果删除成功就皆大欢喜,如果删除失败,则将需要删除的key发送到消息队列。另外有一个消费者线程从消息队列中获取要删除的key,并根据key删除或更新Redis中的缓存。如果操作失败,则重新发送到消息队列中进行重试。
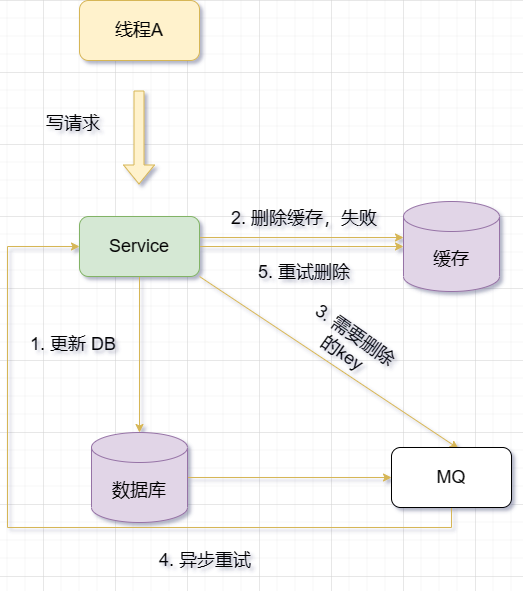
- 使用消息队列异步重试缓存的情况是指,当信息发生变化时,先更新数据库,然后删缓存,如果删除成功就皆大欢喜,如果删除失败,则将需要删除的key发送到消息队列。另外有一个消费者线程从消息队列中获取要删除的key,并根据key删除或更新Redis中的缓存。如果操作失败,则重新发送到消息队列中进行重试。
- 使用延时双删来增加删除成功率和减少不一致时间窗口。即在更新数据库前删除一次缓存,并在一定时间间隔后再次删除一次。
- 先删除缓存,再更新数据库,之后根据业务场景延迟一段时间再删除一遍。
- MQ+Canal 策略,将 Canal Server 接收到的 Binlog 数据直接投递到 MQ 进行解耦,使用 MQ 异步消费 Binlog 日志,以此进行数据同步;
第三种 使用canal组件同步mysql数据到redis中。实现的原理:canal通过伪装成mysql salve,向mysql master发送dump协议,mysql解析协议并发送binlog日志(存放的是对数据库操作的语句,比如增删改),canal解析binlog 在将数据同步到redis中。优点是解耦,不需要额外操作其他。
- 使用消息队列来异步地删除或更新缓存,避免阻塞主线程或者丢失消息。
- 项目:
- 比如人工配置退改库规则,先是直接入库,然后放到redis中,过期时间兜底(时间可以长一点,因为退改规则不是经常变动),然后当人工配置一条数据后,立马删除redis中的旧缓存,等下次读取会查询数据库,再将数据放入到缓存中。
- 也可以使用guava或者map实现本地缓存。比如从apollo中获取配置信息缓存到本地map中去,避免每次去查apollo。
10. 讲讲redis的线程模型?
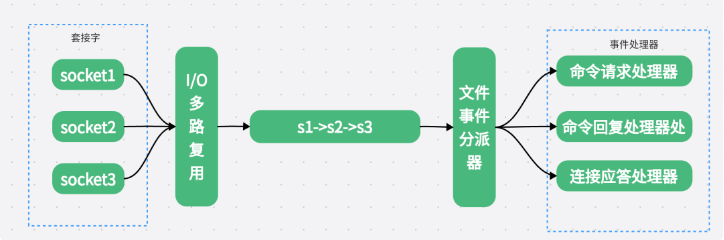
- redis的单线程模型是基于Reactor模型开发的网络事件处理器。也叫做文件事件处理器。有四部分组成,socket套接字,io多路复用,文件事件分派器,时间处理器。因为文件事件分派器是单线程的消费队列消息所以redis是单线程的。
11. memacached和redis的区别?
- 虽然都是内存数据库,但是redis处理速度比memcached更快。
- Redis的数据类型更丰富。
- redis有持久化机制,memcached没有,且重启数据会丢失。
- redis支持主从复制,哨兵模式等
- redis采用的io多路复用,memcached采用的非阻塞io。
- redis的value最大为512m,memcached仅1m
12. redis的内存淘汰机制?
- 当Redis 的运行内存已经超过 Redis 设置的最大内存之后,则会使用内存淘汰策略删除符合条件的 key,以此来保障 Redis 高效的运行。
- 内存淘汰策略有八种:
- 按照淘汰过期key和所有key。
- 针对所有key:1.随机淘汰key。2.不淘汰数据,报错。3.淘汰最近最少使用的(时间维度) 4.淘汰最近经常不使用的(频率维度)
- 针对过期时间:1.随机删除过期key。2.使用LRU算法删除所有设置过期时间的key(常用) 3.删除及将要过期的key(时间维度)4.删除最不常用的过期时间key(频率维度)。
13. redis的过期删除策略?
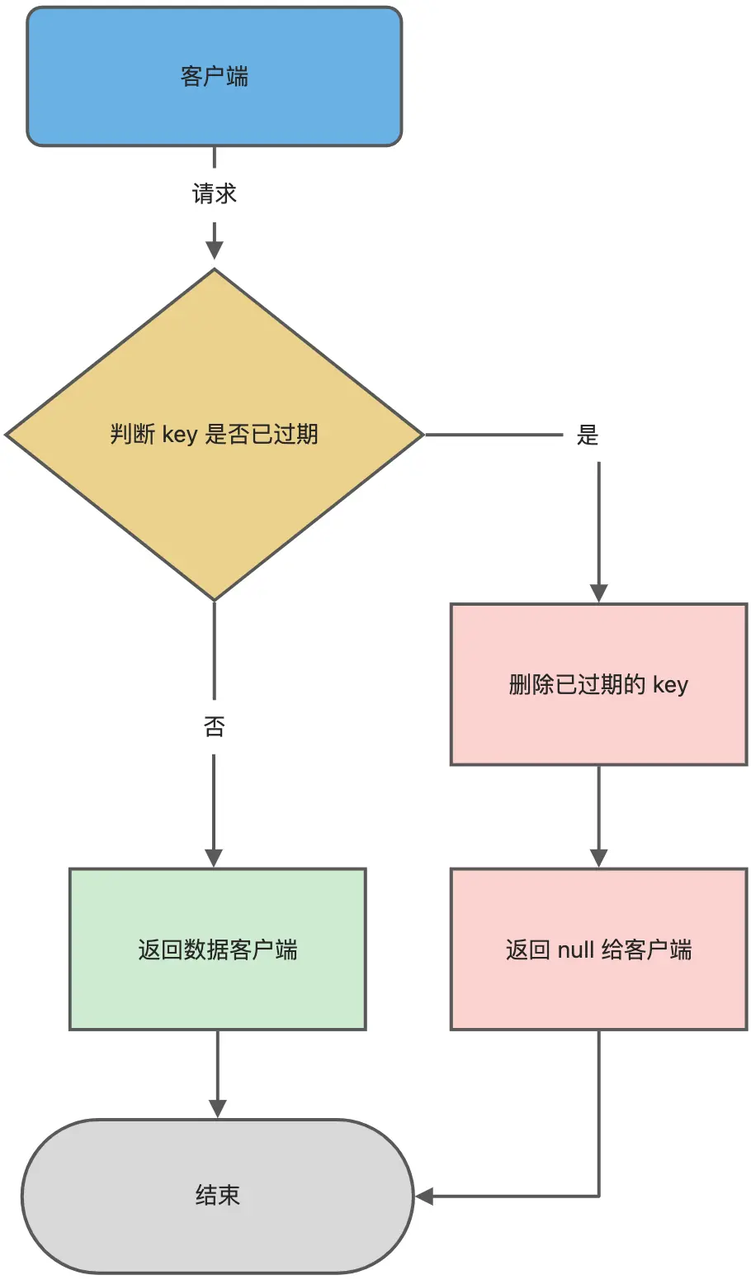
- redis采用惰性删除(每次使用查询或者修改key的时候,查询key是否过期,过期了就删除)和定期删除(定时从数据库中随机抽取20个key进行过期检查,超过5个就再再来一次,否者就等待下一次时间开启)
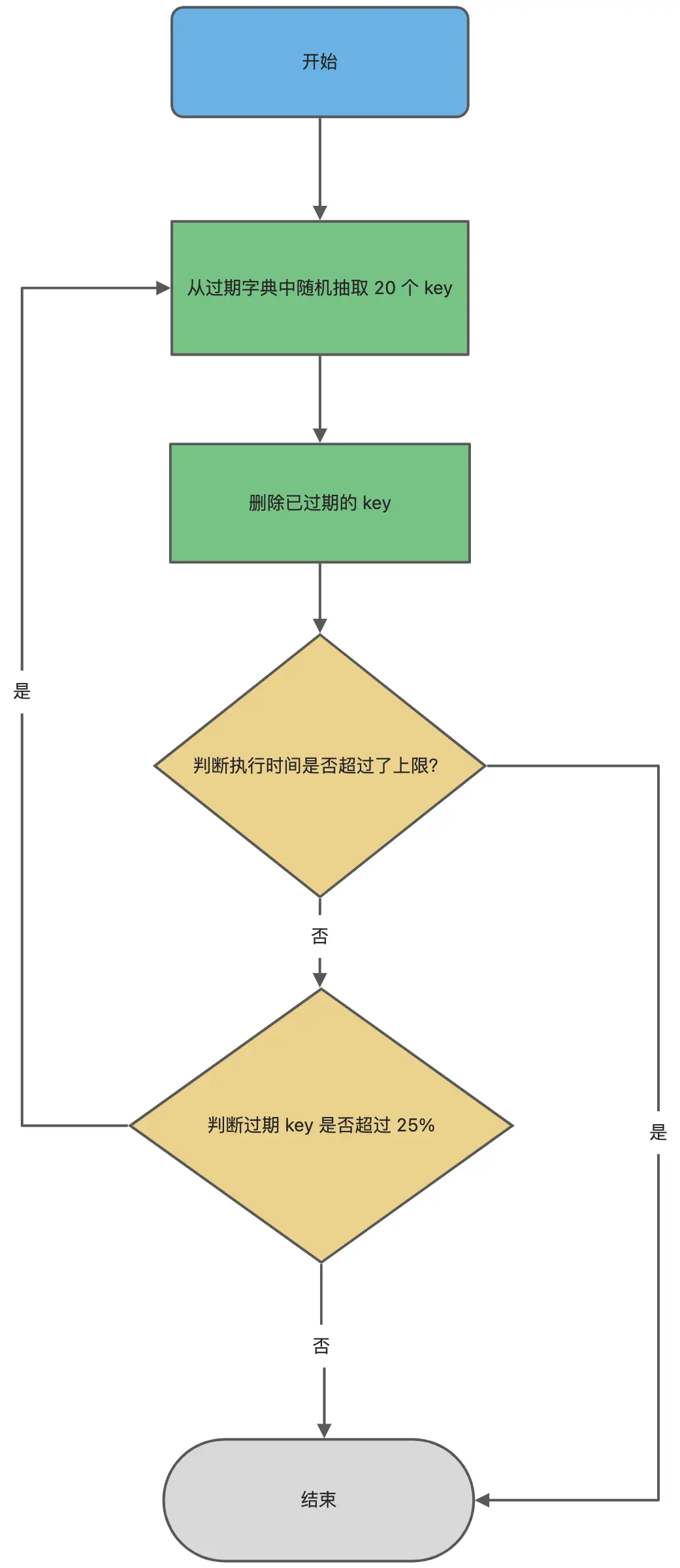
14. redis的事务和lua脚本实现redis事务的区别和联系?
- 什么是redis的事务?
- redis的一些命令组合成一个整体就是redis的事务。
- redis事务具有原子性吗?multi并不支持原子性。因为redis事务中的某条命令失败,不会影响其他命令继续执行。不保证原子性的要么所有操作都执行,都不执行。

- lua事务具备原子性吗?不出异常的情况下具备原子性。
- 很少使用!都是用lua脚本
- lua是c语言编写的脚本语言,可以帮助应用程序进行拓展。
- lua实现redis事务跟redis的multi的优势
- lua支持ifelse
- lua事务如果失败,则会中断后续流程。
15. lua支持acid吗?支持事务回滚吗?
- 如果没有出现异常 是支持的。
- 不支持事务回滚,虽然可以通过discard结束和清空事务,但仍然对数据没有补偿机制和回滚。算是半成品的事务。
16. redis支持隔离性吗?
- redis支持隔离性。所谓的隔离性就是多个事务之间不会相互干扰影响。redis的事务是exec提交之后才会执行。所以提交之前可以通过match监控key是否被修改,从而达到隔离性。提交之后由于redis是单线程的,所以会依次执行。
17. 持久化机制?https://xiaolincoding.com/redis/storage/aof.html#aof-日志
- 持久化机制就是将内存的数据,存储到磁盘中,防止数据丢失。
- redis采用RDB和AOF两种持久化机制。ROB根据规则定期将数据持久化到磁盘中。AOF是每次命令之后就将命令持久化到磁盘中。redis默认是RDB,AOF两者一起使用。
- RDB原理:当我们执行bgsave命令时,redis父进程就会判断是否有子进程正在执行,如果在,则返回。否则父进程就会fork一个子进程(fork的过程父线程时阻塞的),将命令写到临时rdb文件。当所有命令都记录完毕,之后再替换旧的RDB文件。
- 触发rdb的方式:1.执行save(线上环境不推荐,因为执行save会立刻执行,会阻塞父线程处理业务)和bgsave命令(推荐)。2.通过save设置持久化规则(save 100 10 10100秒10个key修改)3.shutdown的时候执行。
- 优点:异步持久化到磁盘,为redis提供高性能。
- 缺点:不能实时持久化,redis异常退出,rdb方式就可能会丢失最后一次更新的数据。
- AOF原理:每执行一条写操作命令(读命令不记 没用),就将该命令以追加的方式写入到 AOF 文件,然后在恢复时,以逐一执行命令的方式来进行数据恢复。
- 其中回写磁盘的策略一共有三种:
- Always,这个单词的意思是「总是」,所以它的意思是每次写操作命令执行完后,同步将 AOF 日志数据写回硬盘;
- Everysec(推荐使用),这个单词的意思是「每秒」,所以它的意思是每次写操作命令执行完后,先将命令写入到 AOF 文件的内核缓冲区,然后每隔一秒将缓冲区里的内容写回到硬盘;
- No,意味着不由 Redis 控制写回硬盘的时机,转交给操作系统控制写回的时机,也就是每次写操作命令执行完后,先将命令写入到 AOF 文件的内核缓冲区,再由操作系统决定何时将缓冲区内容写回硬盘。
- 高性能和高可靠都兼容。最多丢失1秒的数据。
- aof的重写机制:当aof文件越写越大的时候,通过fork一个子线程将数据进行重写到一个新aof文件,之后再覆盖旧文件。
- 其中回写磁盘的策略一共有三种:
18. Redis的部署方案?
- 单机部署,一台redis承受qps为几万不等。问题是容量有限,性能优先,高可用优先。如果挂了就完蛋了。
- 主从复制:一主多从,读写分离。主master负责写数据,从slave负责读数据。
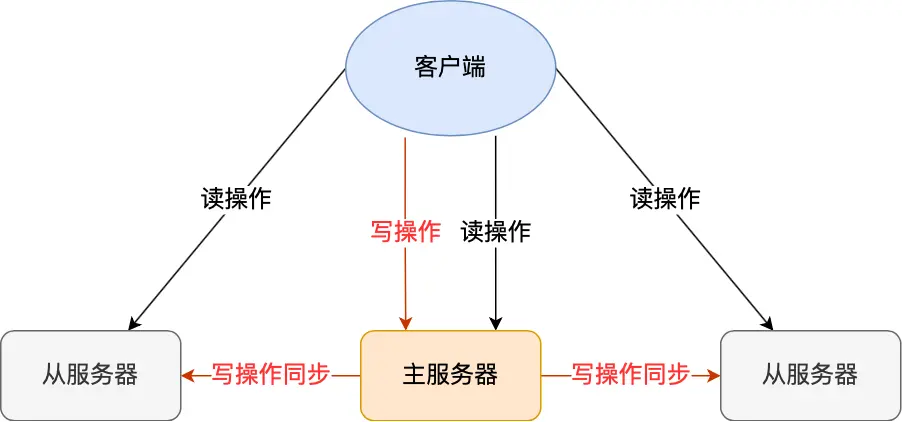
- 主从复制数据同步过程:1.首次主从同步,采取的全量复制,也就是主服务器通过RDB文件复制给从服务器,从服务器更新RDB文件达到同步。2.之后就保持tcp的长连接,直接将写命令同步到从服务器中。3.当网络断开时怎么办呢?采用增量复制的方式,也就是缓存中主写入数据到从服务器要读之间的数据。
- 主从复制共有三种模式:全量复制、基于长连接的命令传播、增量复制。
- 主从服务器第一次同步的时候,就是采用全量复制,此时主服务器会两个耗时的地方,分别是生成 RDB 文件和传输 RDB 文件。为了避免过多的从服务器和主服务器进行全量复制,可以把一部分从服务器升级为「经理角色」,让它也有自己的从服务器,通过这样可以分摊主服务器的压力。
- 第一次同步完成后,主从服务器都会维护着一个长连接,主服务器在接收到写操作命令后,就会通过这个连接将写命令传播给从服务器,来保证主从服务器的数据一致性。
- 如果遇到网络断开,增量复制就可以上场了,不过这个还跟 repl_backlog_size 这个大小有关系。
- 如果它配置的过小,主从服务器网络恢复时,可能发生「从服务器」想读的数据已经被覆盖了,那么这时就会导致主服务器采用全量复制的方式。所以为了避免这种情况的频繁发生,要调大这个参数的值,以降低主从服务器断开后全量同步的概率。
- 主从复制数据同步过程:1.首次主从同步,采取的全量复制,也就是主服务器通过RDB文件复制给从服务器,从服务器更新RDB文件达到同步。2.之后就保持tcp的长连接,直接将写命令同步到从服务器中。3.当网络断开时怎么办呢?采用增量复制的方式,也就是缓存中主写入数据到从服务器要读之间的数据。
- 怎么判断 Redis 某个节点是否正常工作?
- ping心跳检测机制。如果一半以上的节点不通,就是挂了。
- 主从复制架构中,过期key如何处理?
- Redis 是同步复制还是异步复制?
- 主从数据不一致问题?1.不可能做到时时刻刻都一致,所以尽可能保证网络稳定,或者使用外部监控,当数据差距阀值过大,就断开从节点。
- 哨兵模式:
- 哨兵模式是为了解决只有一个主服务器的master挂点了,如何自动的故障转移和选主。哨兵本质是一个redis进程,主要做三件事。
- 监控主从服务器是否存活(通过多个哨兵ping心跳机制的结果进行判断)。
- 选主:哨兵之间选取leader,然后重新选主master。
- 通知:通过 Redis 的发布者/订阅者机制将主从切换的ip和端口告知客户端。
- Redis cluster:解决前两种模式redis存储的都是同样的数据空间比较浪费,以及单主redis写能力问题。redis cluster使用虚拟槽算法实现了分布式存储。
- 一般是三主三从。主节点提供读写,从节点只做备用节点。
- Redis cluster采用hash将数据分片映射到0-16383个卡槽内。
- 每个主节点都开放两个端口,一个用来节点之间的通信,故障转移等,另一个用来读写。
19. 缓存常见问题?
1.缓存穿透
- 描述:查询的数据缓存和数据库中都不存在时,大量请求直接访问数据库,造成数据库压力。
- 解决方式:1.将缓存结果记为null,并设置过期时间。2.使用布隆过滤器
- 布隆过滤器:类似一个set,使用contains()判断请求是否已存在。
- 原理:本质是一个位数组+hash函数。通过hash将请求映射到位数组中,使用1表示存在。其他为0。当下一次相同请求进来时,如果映射之后存在0则一定不存在,直接拦截返回。否则可能存在(因为元素有可能映射是相同的)
2.缓存击穿
- 大量请求获取某个key时,这个key过期了,造成大量请求直接访问数据库。
- 解决方式:分布式锁,热点数据永不过期。
public Stringget(String key) {
String value = redis.get(key);
if (value == null) { //缓存值过期
String unique_key = systemId + ":" + key;
//设置30s的超时
if (redis.set(unique_key, 1, 'NX', 'PX', 30000) == 1) { //分布式锁
value = db.get(key);
redis.set(key, value, expire_secs);
redis.del(unique_key);
} else { //其他线程已经到数据库取值并回写到缓存了,可以重试获取缓存值
sleep(50);
get(key);
//重试
}
} else {
return value;
}
}
3.缓存雪崩
- 描述:大量缓存数据在同一时间过期(失效)或者 Redis 故障宕机时。
- 解决方案:
- 针对过期失效可以采用 1.均匀设置过期时间,防止同一时间过期 2.分布式锁 3.过期时,设置本地缓存,先查本地缓存,最后查询数据库。
- redis故障引发雪崩:1.服务熔断(拒绝所有请求访问数据库)2.请求限流(少量请求访问数据库,其他拒绝)3.搭建redis的高可用集群。
20. redis变慢的原因?
- 是否存在大key。大key会造成客户端阻塞影响性能,网络堵塞。
- 网络带宽问题。redis除了依赖内存之后,还有因为网络的io影响性能。
- 设置了redis的内存使用上限maxmemory 导致redis必须淘汰内存,导致redis变慢。
21. 为什么虚拟槽是16384个?
- 太大浪费带宽。因为redis集群之间会有ping/pong心跳检查机制,同时在心跳包中也会传递这个虚拟槽中的数据,所以如果太大就容易浪费带宽。
22. redisson的分布式锁原理?
- redssion实战:1引入依赖
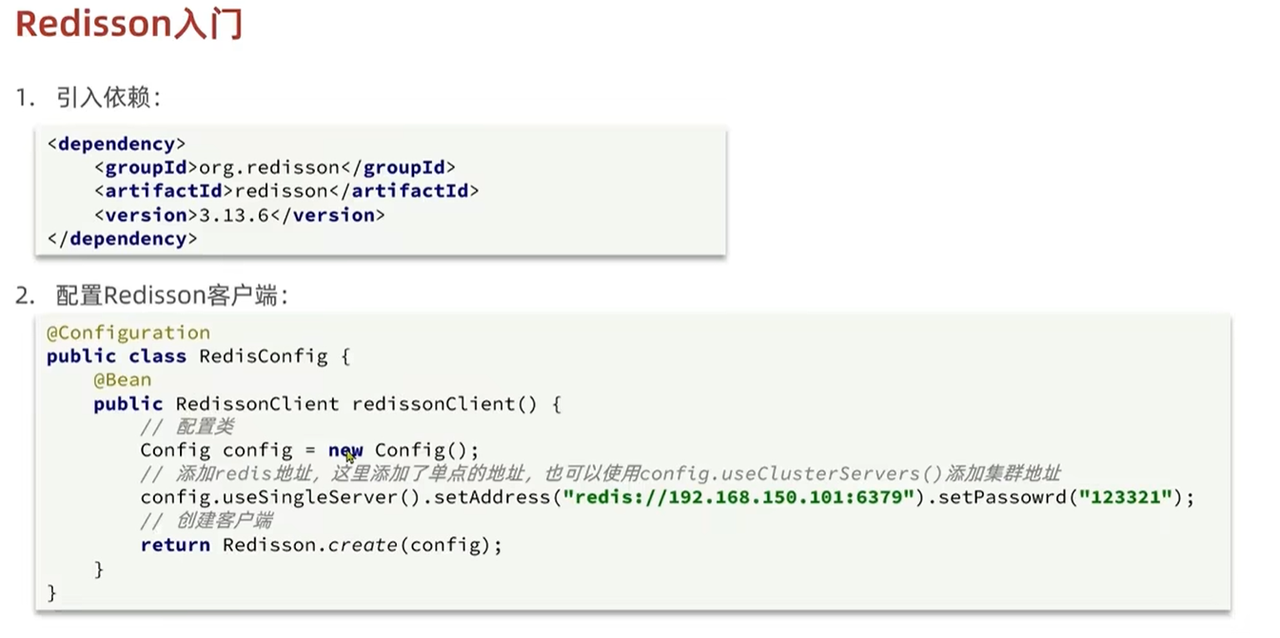
- 2.通过redisson.create(config)创建redisson客户端(redissonClient)之后就可利用客户端中的方法(lock())加锁解锁了。
RLock lock = redissonClient.getLock(Convert.toStr(serviceOrderInfoModel.getOtaOrderId()));//获取锁对象
if (lock.tryLock()) { //尝试加锁 默认的tryLock()中的参数为-1,30 s 表示立刻返回加锁结果,以及宕机30秒自动释放锁。
try{
//业务
} finally {
if (lock.isLocked()) {
//防止当前线程释放掉其他线程的锁
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
}
- 底层原理:
- 1.redssion的可重入锁:
- 通过redis的事务和lua脚本实现。本质是通过一个hash结构存储线程和可重入次数。当同一个线程多次获取锁的时候,通过线程id判断是否是同一个持有者,是的话将获取锁并将可重入次数+1,释放的时候-1 直到0的时候才删除锁。
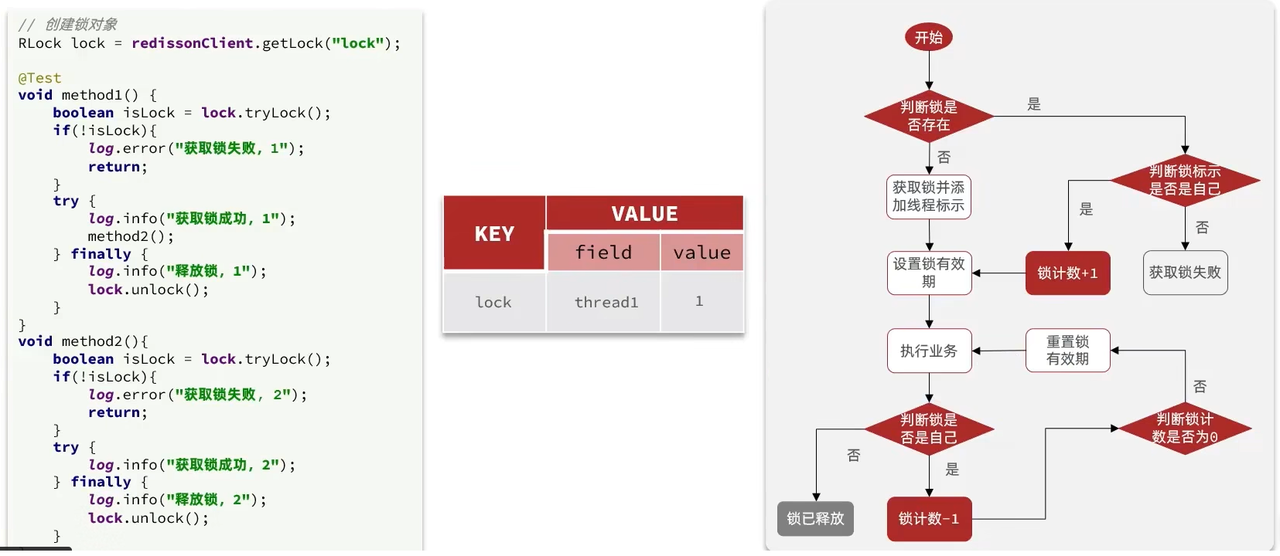
- 通过redis的事务和lua脚本实现。本质是通过一个hash结构存储线程和可重入次数。当同一个线程多次获取锁的时候,通过线程id判断是否是同一个持有者,是的话将获取锁并将可重入次数+1,释放的时候-1 直到0的时候才删除锁。
- 2.重试机制:我们可以通过trylock中参数设置重试时间,以及锁自动释放的时间。
- 看门狗机制:当我们线程获取了锁,但是在锁自动释放时间(默认30s)还没执行完业务代码时,看门狗会检测线程是否持有,持有的话每隔10秒续期30s。如果不持有了释放。
问题复盘
1.redis的五种数据结构–🆗
2.业务中如何保证redis数据不丢失,或者持久化方案? --不清楚
3.业务侧重于cp?ap? 一致性要求高不高?强一致性,弱一致性 ap可用性分区容错性
4.下游接口数据快过期了,如何保证用户快速响应拿到最新的接口数据?redis的数据过期了,或者没去请求这个redis数据,那这些数据如何更新,保持一致性呢。
5.订单超时问题 mq的延迟队列?
6.缓存穿透,击穿,雪崩 对应的解决方案 互斥锁,集群 —🆗
7.布隆过滤器的核心 不存在就一定不存在,存在可能不存在(误判) 布隆过滤器是一个临时方案 用来缓解数据库压力,当流量洪峰过了之后,分析穿透原因,手动把热点数据放到redis中。
8.过期删除策略?–🆗
9.内存淘汰机制?—🆗
10.缓存更新?三种策略 1.设置缓存时间等待redis从数据库中加载到内存 2.主动更新redis数据
11.rdb和aof持久化–🆗 rdb拷贝copyonwrite?
12.分布式锁的看门口?必要元素–可重入,一定满足cp?
13.zookeeper 和redis做分布式锁的原因?
redis成立的早,redis基于内存等优点快。用户人群广
14.redis的指令具有原则?–incr 计数器用过吗?
有原子性。incr可以统计点赞数。
15.redis的网络模型 reacot模型有几种
16.netty
jvm:垃圾回收器 cms gone重点 。1.类的加载过程 2.垃圾回收器,算法。3.jvm实战,工具 问题排查。
分析拆解
1. 什么是AP,CP?想想公司业务是侧重ap/cp?
- ACP A:可用性(最终一致性),P:分区容错性 C:一致性
- AP和CP针对的是redis集群而已。单机没有这种概念。
- 分布式在redis是倾向于AP的。无法做到一致性的原因:
- 在进行节点之间同步数据时,会受到网络波动导致,导致数据存在一致性问题。
- 此外当主节点挂点时,瞬时产生的数据就会丢失,虽然故障转移之后,重新选举master,且该宕机的redis加入到从节点中,但是瞬时的数据已经丢失了。
2. 数据一致性问题?
- 强一致性:我写什么就马上展示什么,弱一致性:中间数据会丢失 类似打电话卡了丢失中间内容,最终一致性:过程可能会拿到旧的数据,但是最终数据肯定会一致。
3. 数据更新?
4. redisson的看门狗机制?
- Redisson的分布式锁原理:
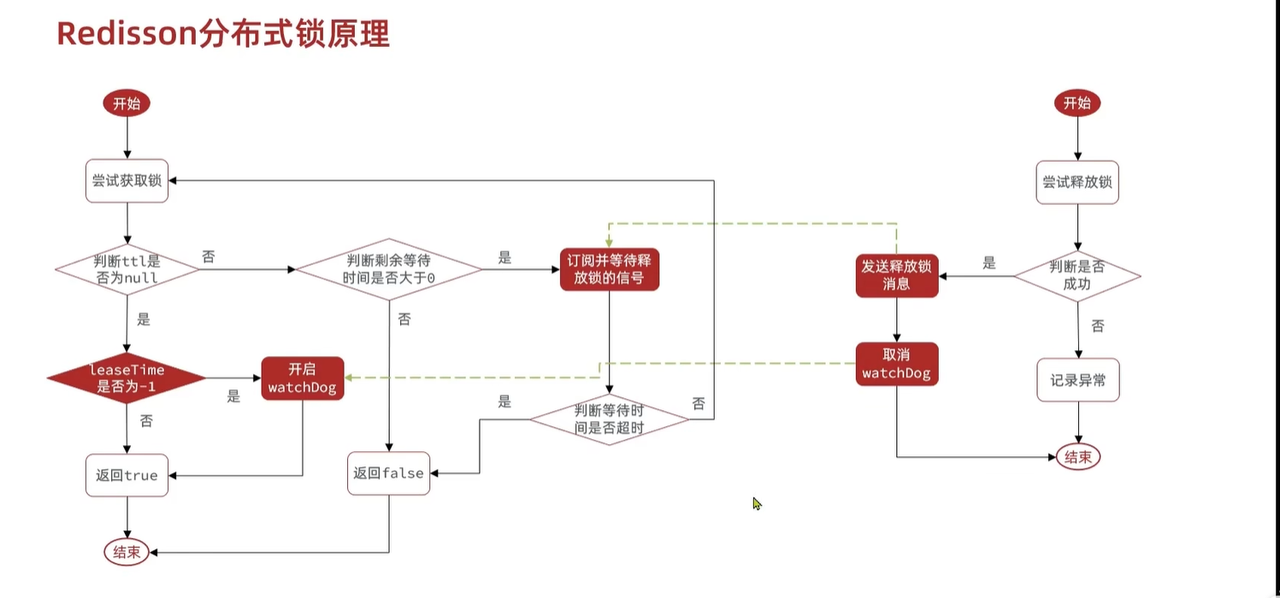
- 看门狗机制:
- 延迟双删?
- redis的网络模型?
- netty?
- 订单超时问题 mq的延迟队列?
- zookeeper 和redis做分布式锁的原因?
- 布隆过滤器核心?
- redis集群?只知道背八股文,但是稍微细化一点的场景没法说出出现的问题和解决方式
- redis的实战使用 https://www.bilibili.com/video/BV1cr4y1671t?p=23&vd_source=d895293f5f20ef79bd6ffbeb4865aae9
- 导入以来,配置redis的地址和连接池参数,注入redisTemplate对象。之后从redisTemplate.opsxx获取数据类型并设置值了。
- redis的序列化问题:解决redis默认将对象存储二进制形式(乱码)


评论区