



java并发编程艺术电子版链接
资料1:并发思维导图(JUC 并发)
资料2:https://www.yuque.com/hollis666/wty0im/dye7p0b0it112wcy
线程
基础
1. 什么是线程和进程?
- 进程具有独立的执行环境。比如微信,qq可以看作一个进程集合。线程是存在进程中的,线程是最小的执行单位。
- 比如main就是一个进程,包括了main执行线程和gc线程。
2. 什么是多线程的上下文切换?
- 指的cpu在一个线程切换到另一个线程时,保存当前线程的执行状态,程序计数器,指针等。保证切换会原线程时能够正常的运行。
如何降低上下文切换?- 使用线程池减少线程的创建和销毁。无锁编程。使用cas算法。
3. 用户态和内核态 如何切换?
- 用户态指的是应用程序运行在非特权模式下的状态。内核态指的是操作系统运行在特权模式下的状态。这样区分的目的是为了保证系统的安全运行。
- 当应用程序需要操作底层硬件资源的时候,就会从用户态切换内核态取读取资源,操作完之后再切换回来,内核态时线程时阻塞暂停的。
4. cpu和线程的关系?
- 同一时刻一个cpu只能执行一个线程。
5. 创建线程的几种方式?
- 继承thread接口,重写里面的run方法
- 实现runnable接口 run方法
- 实现callable接口 重写里面的call方法
6.runnable和callable的区别?
- runnable的run方法无返回值 callable的call方法有返回值 object
- callable方法还可以抛出异常 runable不行
线程池 线程池
7.创建线程池的方式?
- 1.new ThreadPoolExecutor(参数,,)实现 常用 项目中确实用到了。
/**
创建出票线程工厂
*/
ThreadFactory issueThreadFactory = ThreadUtil.newNamedThreadFactory("trade_order_thread_factory", new ThreadGroup("issue"), true);
/**
查询票号任务线程池
*/
ThreadPoolExecutor queryTicketNoThreadPool = new ThreadPoolExecutor(10, 10, 0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(), issueThreadFactory, new ThreadPoolExecutor.CallerRunsPolicy());
-
- Executors.方式创建 固定线程数量大小的线程池,单线程的线程池,可缓存的线程池,定时执行任务的线程池 不常用
- 图中就可以看到为什么不常用了,因为本质还是new threadpoolExecutor(),只不过是将参数帮我们写好了的,但生产中需要我们根据具体的业务需求压测之后填写参数。所以推荐自己new threadPoolExecutor
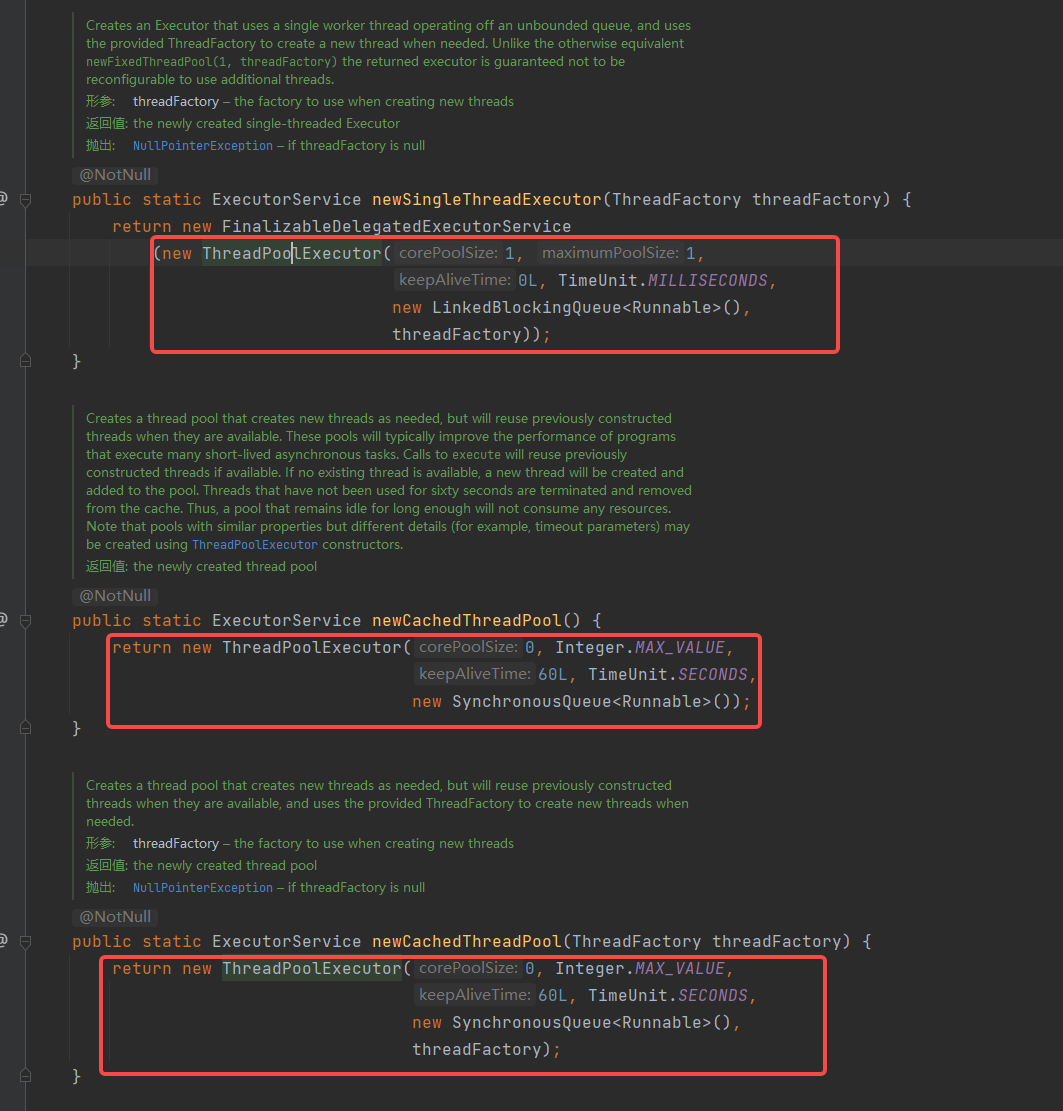
8.线程池的参数有哪些?
- corePoolSize:核心线程数量,可以类比正式员工数量,常驻线程数量
- maximumPoolSize:最大的线程数量,公司最多雇佣员工数量。常驻+临时线程数量。
- workQueue:多余任务等待队列,再多的人都处理不过来了,需要等着,在这个地方等。
- keepAliveTime:非核心线程空闲时间,就是外包人员等了多久,如果果还没有活干,解雇了。
- threadFactory:创建线程的工厂,在这个地方可以统一处理创建的线程的属性。每个公司对员工的要求不一
- 样,恩,在这里设置员工的属性。
- handler:线程池拒绝策略,什么意思呢?就是当任务实在是太多,人也不够,需求池也排满了,还有任务咋
- 办?默认是不处理,抛出异常告诉任务提交者,我这忙不过来了了。
9.工作中如何使用线程池的?
- 工作用使用new threadPoolExecutor()方法创建线程,指定核心线程数,最大线程数,非核心线程空闲时间,时间单位,阻塞队列,线程工厂,拒绝策略。拒绝策略一般使用的是new ThreadPoolExecutor.CallerRunsPolicy()。
- 注:为什么与CountDownLatch进行组合使用呢?
10.使用线程池的好处和问题?
- 线程可以复用
- 减少创建和销毁线程的开销
11.线程提交任务的流程?
public void execute (Runnable command){
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
// 如果核心线程未全部启动启动核心线程,执行本次提交任务
if (addWorker(command, true))
return;
c = ctl.get();
}
// 核心线程已占满
// 线程池未关闭,则将本次任务添加到任务队列
if (isRunning(c) && workQueue.offer(command)) {
// 双重校验,如果线程池关闭了,那么将本次任务移出任务队列。
int recheck = ctl.get();
if (!isRunning(recheck) && remove(command))
// 成功移出任务队列,执行决绝策略
reject(command);
else if (workerCountOf(recheck) == 0)
// 如果没有可运行线程,启动一个非核心线程执行本次任务
addWorker(null, false);
}
// 无法添加到任务队列,那么启动非核心线程
else if (!addWorker(command, false))
// 线程数已满,执行决绝策略
reject(command);
}
- 执行execute方法之后,
- 先判断当前执行线程是否小于核心线程数,小于则将任务放到addwoker方法创建核心线程执行并结束。
- 如果不满足,则判断线程池是否关闭,没关闭时放入到等待队列中。
- 如果等待队列也放不下就启动非核心线程执行,直到最大线程数。
- 如果最大线程数还不够,则执行拒绝策略。
- 我在生产中拒绝策略使用的时callrunspolicy() 也就是交给提交任务的线程去执行。其次还可以选择直接舍弃任务
12.线程池的work机制?todo
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
13.为什么不建议直接使用Spring的@Async?https://www.yuque.com/hollis666/wty0im/naw927g44ywpxw4e
- @Async注解表示异步执行,在方法上使用。当一个线程调用该方法的时候,就会创建一个新的线程异步执行这个方法。一般配合@EableAsnc 开启异步执行,但是不建议使用默认的@Async,因为没有最大线程数的设置,在大量并发会造成严重性能问题。
- 所以建议自定义异步线程池:
@Configuration
@EnableAsync
public class AsyncExecutorConfig {
@Bean("registerSuccessExecutor")
public Executor caseStartFinishExecutor() {
ThreadFactory namedThreadFactory = new ThreadFactobryBuilder
.setNameFormat("registerSuccessExecutor-%d").build();
ExecutorService executorService = new ThreadPoolExecutor(100,200,
0L,TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>(1024), namedThreadFactory, new ThreadPoolExecutor.AbortPolicy())
return executorService;
//使用
@Async("registerSuccessExecutor")
public void onApplicationEvent(RegisterSuccessEvvent event){
RegisterInfo registerinfo = (Registerinfo) event.getsource();
}
14.submit和execute方法的区别?
- 两者都是向线程池提交任务。
- 不同点:execute提交后无返回值,用法比较简单。而submit提交后会有返回值 futrure ,通过future.get()捕获异常。
15.线程异常处理方式?
- 手动trycatch,缺点是主线程中不能捕获子线程异常。
- 使用submit提交任务后返回future类,就可以让主线程捕获子线程异常。
线程池的状态转换
- Running、ShutDown、Stop、Tidying、Terminated
- 线程池一旦被创建就会进入runing状态,等待接受任务。
- 调用线程池的shutdown方法就进入shutdown状态,但是仍然会处理已经添加的任务。
- 当调用shutDownNow方法时候就进入stop状态,并且会中止已经添加的任务。
- 当所有的任务数量为0的时候,就会进入tiding。
- 调用terminated方法就会进入terminated状态。
线程的生命周期
- 1.调用了start方法创建一个线程(并没有真正执行)此时进入runnable状态。
- 2.当cpu分片执行该线程后就进入了running状态。
- 3.当调用sleep和wait方法时就会进入blocked状态。
- 4.当线程执行结束就会进入terminated状态,结束线程的生命周期。

线程池体现的设计模式
- 模板方法模式
核心线程和非核心线程的区别?
- 本质上都是一样的,线程池中也不会标记那些线程是核心和非核心线程。唯一的区别在于非核心线程有一个最大的空闲时间,如果达到这个空闲时间就会销毁,而核心线程是一种存在线程池中的。
核心线程数如何设置的理论公式
- 1.判断是cpu密集型任务还是io密集型任务。cpu:任务一进来需要cpu进行计算。io任务更多是调用接口和数据库。
- cpu密集型任务:n(多少核)+1
- io密集型任务:2n(cpu)
什么是守护线程和普通线程?
- 守护线程指的是后台运行的线程,比如gc线程。普通线程指的就是我们主动创建的线程。
- 两者唯一的区别在于:jvm在执行完所有的普通线程之后就会结束,而不会等待守护线程。
- 我们可以通过 线程对象.setDaemon(true)设置为守护线程。
run/start方法,sleep/wait,notify/notifyAll区别? - 调用start方法是创建一个线程,并不是马上执行线程,是由cpu决定什么时候执行。调用两次start方法报错
- sleep和wait的区别:
- wait() 方法属于 Object 类的一部分,而 sleep() 方法属于 Thread 类。因此,wait() 方法用于线程间的同步和通信,而 sleep() 方法用于线程的暂停。
- wait() 方法必须在同步代码块中调用(即在使用 synchronized 关键字修饰的方法或代码块中),并且调用 wait() 方法后会释放对象的锁,从而允许其他线程获取该对象的锁。而 sleep() 方法可以在任何地方调用,它不会释放任何锁。
- 当调用 wait() 方法时,线程会进入等待状态,并且需要通过 notify/notifyAll唤醒一个线程或者全部等待的线程。
面试常问?
- 线程执行任务什么时候才会让出cpu?
- 答:当线程的时间片用完时;当线程执行I/O时;当线程调用yield()主动让出cpu。
锁
文章推荐:https://tech.meituan.com/2018/11/15/java-lock.html
同步和并发理解?
- 同步指的是控制多个线程对一个资源进行访问顺序,保证数据的一致性和安全性的一种机制。
- 并发指的是一段时间多个任务同时执行。
java中按照某些特性将锁进行分类如下图:
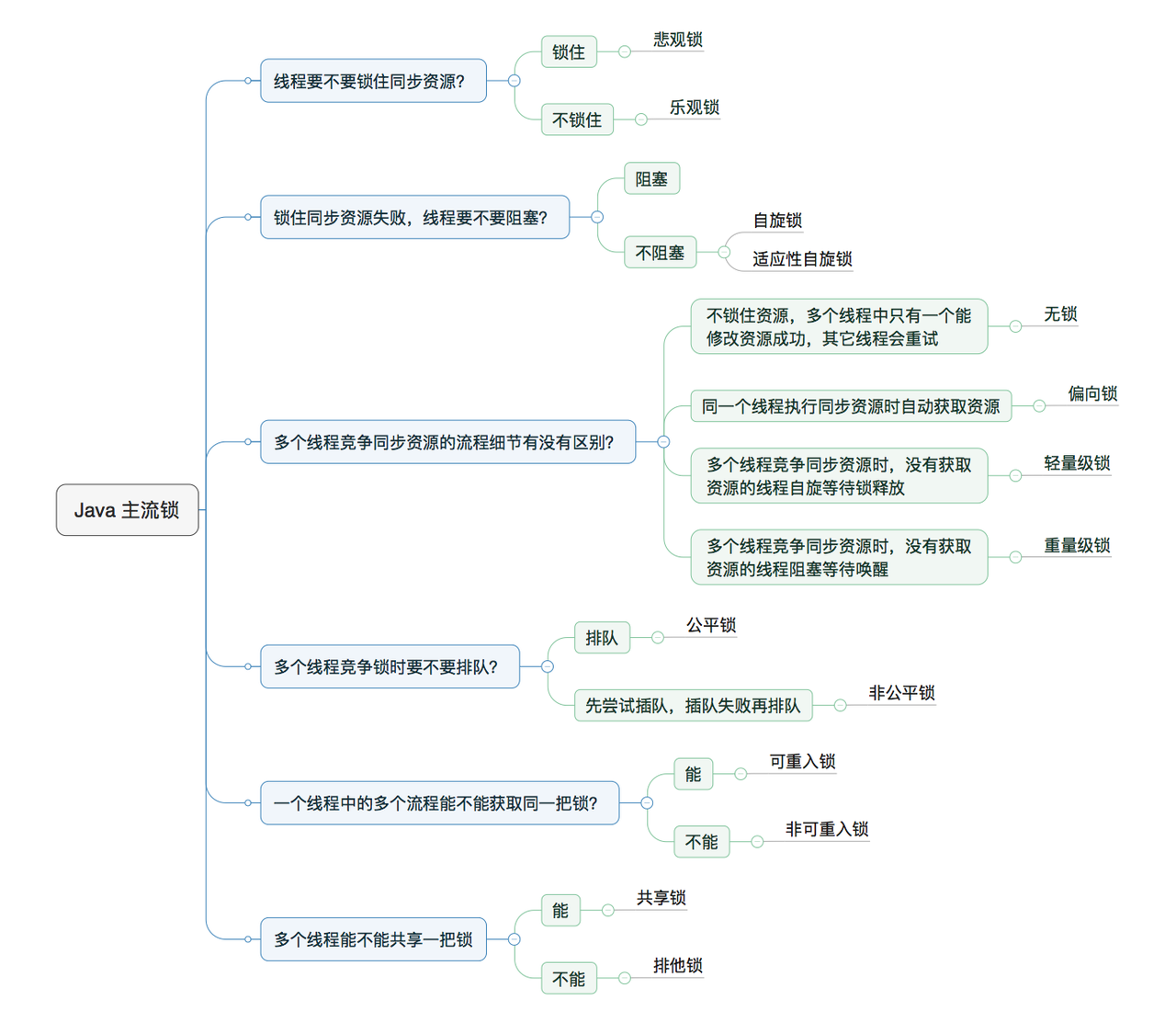
线程要不要锁住同步资源?
- 悲观锁:
- 当对一个对象并发操作时,悲观锁认为别人一定会修改数据,所以先加锁,后修改数据。比如lock和synchronized就是悲观锁。
- 适合写多读少的场景
- 乐观锁:
- 对一个对象资源并发操作时,只有在更新操作时先判断其他线程有误修改,如果没有则更新,如果另一个线程正在修改则通过自旋或者报错操作。比如cas算法
- 适合读多写少的场景。
数据库中的悲观锁和乐观锁如何实现的?
- 悲观锁:select …for update
START TRANSACTION;
SELECT * FROM table_name WHERE condition FOR UPDATE;
-- 对查询结果进行操作
COMMIT;
- 乐观锁:通过版本号实现乐观锁。
START TRANSACTION;
--获取 id和version
select * from t_point where point_name =#{name}
-- where条件中比较version,且更新条件中将version+1
update t_point set point_name=#{pointName},point_type =#{pointType},version=version+1 where id =#{id} and version =#{version}
COMMIT;
- 自旋锁:线程获取同步资源被占用时,通过自旋等待锁的释放,避免cpu的阻塞和唤醒。
- 自适应锁:自适应意味着自旋的时间(次数)不再固定,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。
- 重入锁和非重入锁:
- ReentrantLock和synchronized都是重入锁。非可重入锁NonReentrantLock。
- 当线程尝试获取锁时,可重入锁先尝试获取并更新status值,如果status == 0表示没有其他线程在执行同步代码,则把status置为1,当前线程开始执行。如果status != 0,则判断当前线程是否是获取到这个锁的线程,如果是的话执行status+1,且当前线程可以再次获取锁。而非可重入锁是直接去获取并尝试更新当前status的值,如果status != 0的话会导致其获取锁失败,当前线程阻塞。
- 共享锁和排它锁:
- 排它锁:同悲观锁一样。只有一个线程可以读写
- 共享锁:多个线程可以共读,但是不能修改数据。
synchronized
https://www.bilibili.com/video/BV1aJ411V763?p=11&vd_source=d895293f5f20ef79bd6ffbeb4865aae9
预备知识
- 对象的结构?
- 对象是由对象头和实例数据和对齐填充组成。其中对象头最重要的就是markword 里面记录年龄信息,锁标志,hashcode等。

- 对象是由对象头和实例数据和对齐填充组成。其中对象头最重要的就是markword 里面记录年龄信息,锁标志,hashcode等。
synchronized重量级锁的底层实现原理?
- 当一个线程尝试获取对象的锁时,它会先尝试获取与该对象关联的mutex变量。如果mutex变量已经被其他线程锁定,那么当前线程将进入阻塞状态,直到mutex变量被释放。
- 一旦线程成功获取了对象的锁(即成功获取了mutex变量),它就可以执行synchronized代码块中的内容。在执行完毕后,线程会释放这个锁,同时释放对应的mutex变量
锁升级? https://k1dy9adkxea.feishu.cn/minutes/obcntteh7id9w6doh44td5px?from=from_copylink
为什么要有锁升级?原因是最开始的synchronized是重量级锁,特点是频繁的上下文切换效率低。
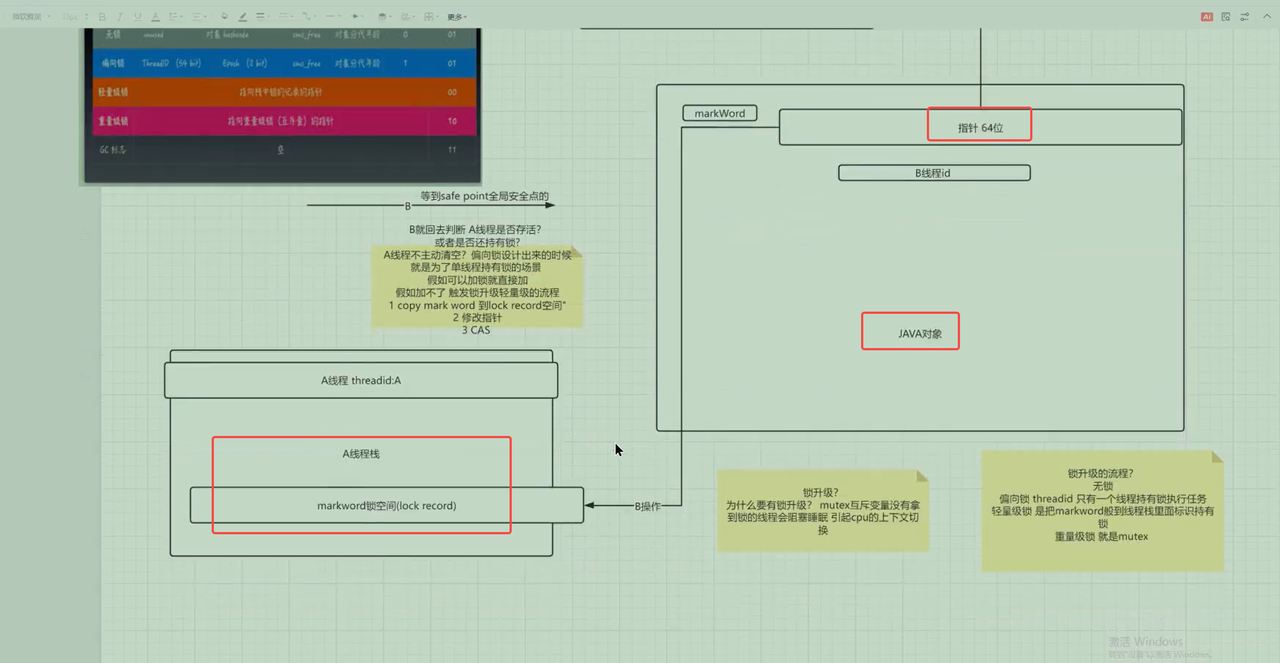
- 无锁:存储对象的hashcode,年龄。
- 偏向锁:一个线程获取对象时,通过将threadId存入到对象头中markword实现加锁。
- 轻量级锁:
- markword中存储的是64bit的指针(指向线程栈中的lock record的指针)
- 原理将对象的markword中的信息复制到线程栈中lock record中,然后markword存在一个指针指向线程lock record。
- 这么做的原因是 一个指针栈64bit存不下,所以将markword中的信息移动到调用的线程栈中。
- 重量级锁:
- markword存储指针(指向mutex互斥变量的指针)。
锁升级过程:
锁状态只能升级不能降级。
- 当一个线程A获取对象的时候,会将threadId存储到对象头中的markword中。
- 如果另一个线程B又来获取该对象,则会在全局安全点的时候,判断线程A是否存活或者是否依旧持有锁,如果没有则替换threadId。
- 如果依旧持有锁,则升级会轻量级锁,线程B并将该对象的markword信息复制到线程A的线程栈的lockreword中,对象只存在指向该lock reword的指针。
- 之后再次进行cas获取锁,如果获取成功则将指针指向线程B的线程栈的lockword中。如果仍然失败,将会默认最多10次自旋获取锁,之后则将对象升级为重量级锁,如果线程C也来竞争轻量级锁则会直接生成重量级锁。
- 此时对象的markword存储的指针指向一个monitor(底层关联这mutex互斥变量)。此时线程B尝试获取monitor(监视器)获取加锁的对象,如果获取了其他线程只能阻塞等待。
锁粗化?
- 锁粗化是一种优化手段,当编译器检查到连续的加锁解锁操作时,将它们合并成一个范围更大的锁操作,减少不必要的锁竞争。
锁消除?
- 当编译器执行代码时,发现某些加锁的资源并不会被多线程竞争,所以就直接去掉加锁。
ReentrantLock
文章推荐: https://juejin.cn/post/6896278031317663751#heading-1
文章推荐:https://juejin.cn/post/7165029692574007326
- synchronized 关键字后为什么还需要 ReentrantLock?
- synchronized使用过操作系统的mutex互斥变量实现,线程的阻塞和唤醒需要内核态到用户态的切换,线程上下文的切换带来开销。所以引入和lock锁(cas+自旋锁)提升加锁的性能。
- ReentrantLock是什么?
- ReentrantLock是可重入锁,是基于AQS实现的。AQS又叫做队列同步器,是一个使用模板方法的抽象类。而ReentrantLock则是实现AQS的其中一种锁。
- ReentrantLock 如何去使用?
- 通过new ReentrantLock(),调用lock()方式去直接尝试获取锁。
- 调用trylock()尝试获取锁,成功返回true,失败立刻返回false。而lock方法在拿不到锁之后就会尝试阻塞当前线程。
- 通过unlock()主动释放锁,相对于synchronized 自动释放锁
- isHeldByCurrentThread():判断当前线程是否持有锁。
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class ReentrantLockExample {
private final Lock lock = new ReentrantLock();
private int count = 0;
public void increment() {
lock.lock();
try {
count++;
System.out.println("Incremented: " + count);
} finally {
lock.unlock();
}
}
public static void main(String[] args) {
ReentrantLockExample example = new ReentrantLockExample();
Thread thread1 = new Thread(() -> {
for (int i = 0; i < 5; i++) {
example.increment();
}
});
Thread thread2 = new Thread(() -> {
for (int i = 0; i < 5; i++) {
example.increment();
}
});
thread1.start();
thread2.start();
}
}
- ReentrantLock跟synchronized的区别?
- 1.实现机制不同,一个是基于monitor监视器,底层mutex互斥变量实现同步。
- 2.ReentrantLock有公平锁和非公平锁。
- 3.双向链表队列保证同步加锁顺序。
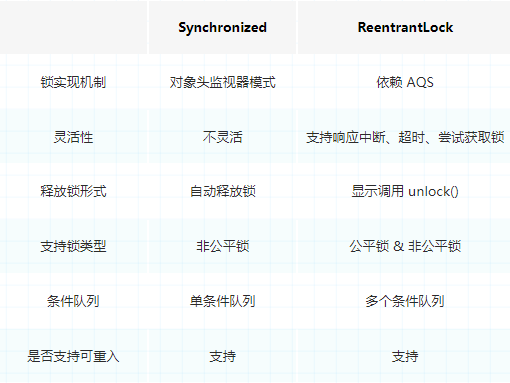
- ReentrantLock底层实现原理?
- 底层是通过AQS中的 Volatile 修饰的int state变量来控制同步状态,使用双向链表的队列来实现线程的唤醒和阻塞。
- ReentrantLock加锁过程图解
- 如图一:需要了解更详细一下,包括node节点
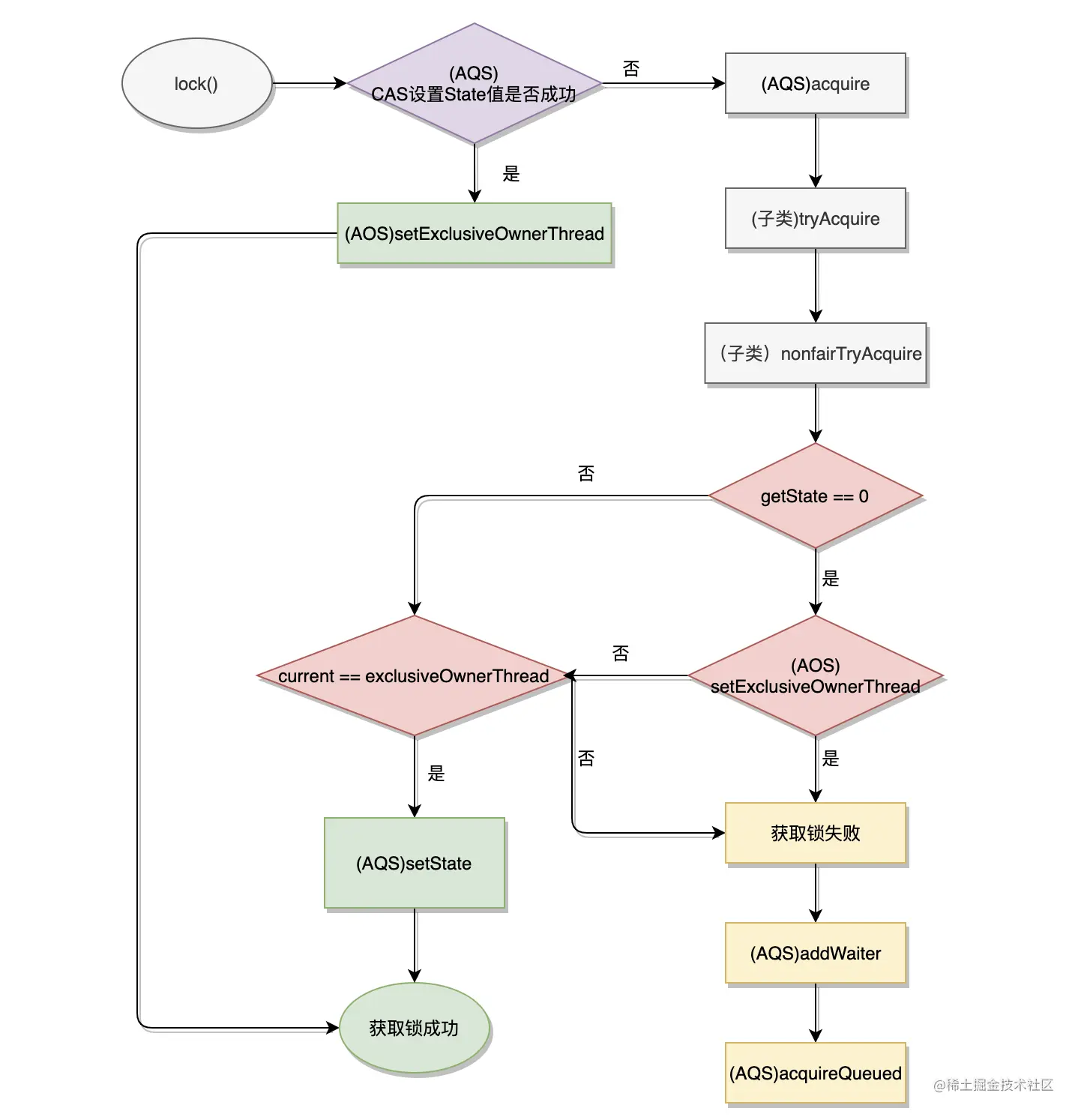
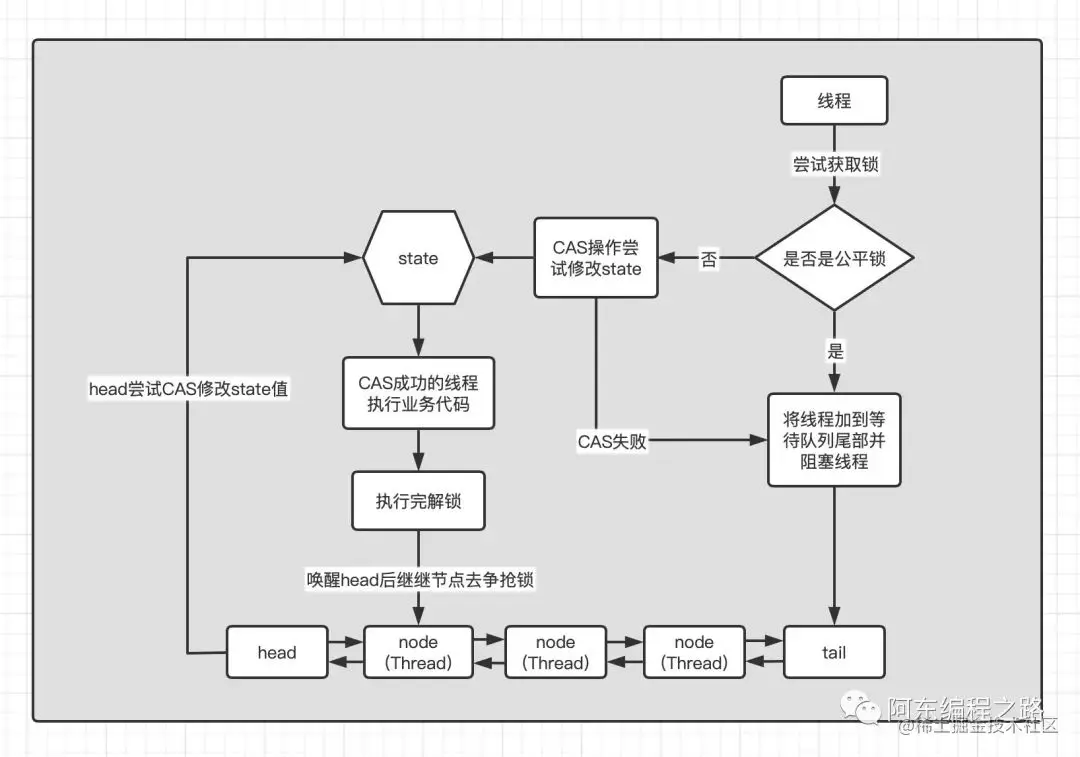
源码:
- 如图一:需要了解更详细一下,包括node节点
final void lock() {
if (compareAndSetState(0, 1)) //cas修改state变量
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}
设置当前线程为独占线程
protected final void setExclusiveOwnerThread(Thread thread) {
exclusiveOwnerThread = thread;
}
如果尝试获取锁失败则调用aquire方法继续尝试获取锁。todo
ThreadLocal ThreadLocal
什么是threadLocal?作用是什么?
- threadLocal是线程的全局变量,每个线程的threadLocal都是线程隔离的,用于解决多线程之间的同步问题(每个线程获取自己设置的变量)。
- 通过threadLocal可以实现变量在线程之间隔离,而在类和方法中共享。
thread和threadLocal以及threadLocalMap之间的关系?
static class ThreadLocalMap {
/**
* The entries in this hash map extend WeakReference, using
* its main ref field as the key (which is always a
* ThreadLocal object). Note that null keys (i.e. entry.get()
* == null) mean that the key is no longer referenced, so the
* entry can be expunged from table. Such entries are referred to
* as "stale entries" in the code that follows.
*/
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
}
- 每个线程thread都有自己的一个threadLocalMap。
- threadLocalMap是有一个entry对象,entry以key-value形式,key存储的就是thread私有的threadLocal实例对象,而value是我们通过set方法赋值的。
threadLocal是如何实现线程隔离的?
- 每个线程都会有自己的ThreadLocalMap变量副本,存储于线程私有的虚拟机栈中,而不是堆中,不会被其他线程
访问到,因此实现了线程隔离。具体操作是,首先创建一个static的全局ThreadLocal变量,创建线程后,线程内调用
set方法时,先获取线程的ThreadLocalMap对象,若没有就创建,ThreadLocalMap类里有一个内部类Entry,他的key
是当前创建的ThreadLocal对象存在于虚拟机栈中,值是我们指定的值,值一般是一个对象比如用户对象,存在于堆
中。且key是弱引用的,值是强引用的。geet时,就根据ThreadLocal对象获取值。
四种引用?
- 强引用是最常用的应用,一个对象具有强引用,gc就不会回收它。比如 Object a=new Object();
- 软引用:当内存不足的时候,垃圾回收器才会回收软引用对象。
- 弱引用:比如threadlocal类就是弱引用。不管内存足不足,只要发现弱引用对象就会回收。注意由于gc线程优先级低,可能未发现弱引用的对象,所以可能造成内存泄露。
- 虚引用(gc回收的标识):并不会决定对象的生命周期,虚引用必须跟引用队列一起使用,当发现虚引用对象就会将它加入到引用队列中,我们就可以通过队列查看虚引用的对象,也就是即将被gc回收的对象。
内存泄漏
- 内存泄漏指的是该回收的垃圾没有回收。
- 内存溢出指的是当内存空间不足,再次产生的对象就会导致内存溢出。
- 此图非常关键,理解该图
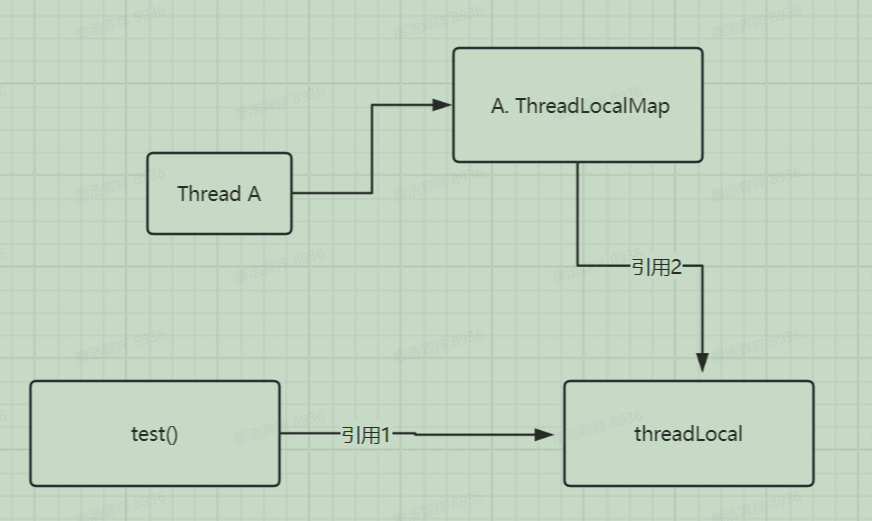
- 此图非常关键,理解该图
- 为什么threadlocalMap的key是虚引用?。因为为了防止内存泄漏。也就是图中方法结束之后引用1就丢失了,threadLocal应该回收,如果是强引用则会一直存在无法回收。
- 那为什么value不是弱引用呢? 因为防止数据丢失。如果key和value都是弱引用的话,当我们get值得时候,threadLocalMap在内存不足的时候回收掉了。
- 如何导致的内存泄露?
- 基于threadlocalmap的key和value分别是虚引用和强引用,所以当thread线程对象存活时,thread localmap是无法回收的,久而久之导致内存泄露。
如何解决内存泄露问题:手动调用remove方法
生活中如何使用threadLocal
- 1.主要是用于用户身份拦截器中使用threadlocal存储用户信息进行透传。
- AuthInterceptor 是个拦截器,根据请求头中的uid判断是是否存在该用户,存在则将用户信息存储到threalocal中,并透传到同一线程中的其他方法中。
@Slf4j
@AllArgsConstructor
@Component
public class AuthInterceptor implements HandlerInterceptor {
@Autowired
private IAuthService authService;
private IJpAdminUserService adminUserService;
private IJpAdminUserConfigService adminUserConfigService;
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object o) {
String bearerStr = request.getHeader("Authorization");
String token = "";
if (bearerStr != null && bearerStr.startsWith("Bearer")) {
token = bearerStr.replace("Bearer", "").trim();
}
String uid = request.getHeader("UID");
if (!authService.verifyToken(uid,token)) {
ResponseUtil.write(response, ResponseInfo.failed(ResponseCodeEnum.AUTH_FAILED));
return false;
}
if (StrUtil.isNotBlank(uid)) {
JpAdminUser user = adminUserService.getById(uid);
if (Objects.isNull(user)) {
ResponseUtil.write(response, ResponseInfo.failed("用户不存在!"));
return false;
}
ContextUserInfo info = new ContextUserInfo();
info.setUserId(user.getId());
info.setUsername(user.getUsername());
info.setNickname(user.getNickname());
UserContext.add(info);
} else {
return false;
}
return true;
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
}
}
java并发面试题
1. hashCode对锁的影响? https://blog.csdn.net/nibonnn/article/details/124026493
- 答:当在上锁之前调用对象的hashcode方法时,锁将会直接升级为轻量级锁。当在偏向锁时,调用对象的hashcode方法则会立刻升级为重量级锁。
- 在上锁前进行hashCode方法的调用
public static void main(String[] args) {
Object lock = new Object();
System.out.println("初始状态:" + ClassLayout.parseInstance(lock).toPrintable());
System.out.println(lock.hashCode());
System.out.println("HashCode调用后状态:" + ClassLayout.parseInstance(lock).toPrintable());
new Thread(() -> {
synchronized (lock) {
System.out.println("上锁:" + ClassLayout.parseInstance(lock).toPrintable());
}
System.out.println("解锁:" + ClassLayout.parseInstance(lock).toPrintable());
}).start();
}
- 在上锁后进行hashCode方法的调用:
public static void main(String[] args) {
Object lock = new Object();
System.out.println("初始状态:" + ClassLayout.parseInstance(lock).toPrintable());
new Thread(() -> {
synchronized (lock) {
System.out.println("上锁:" + ClassLayout.parseInstance(lock).toPrintable());
System.out.println(lock.hashCode());
System.out.println("HashCode调用后状态:" + ClassLayout.parseInstance(lock).toPrintable());
}
System.out.println("解锁:" + ClassLayout.parseInstance(lock).toPrintable());
}).start();
}
volatile关键字的作用?
- 禁止指令重排。在编译器对指令进行优化时,通过内存屏障禁止编译器对指令的重排,保证指令的顺序性。
- 保证共享变量的可见性。也就是线程中对变量的操作都在主内存中进行。
volatile在哪里用到?
- Synchronized中使用到volatile防止指令重排导致的空指针问题。
- 比如 object=new Object() 正确步骤是:给object分配地址空间,初始化,最后指向这边空间。
- 如果不使用volatile对象object就有可能导致 分配空间之后,直接指向这片空间,然后还没初始化时获取这个对象就会空指针异常。
- lock中通过volatile修饰state变量,实现共享变量state的可见性。
评论区