



视频链接:https://www.bilibili.com/video/BV1fG4y1g76v?p=5&vd_source=d895293f5f20ef79bd6ffbeb4865aae9
1. 集合
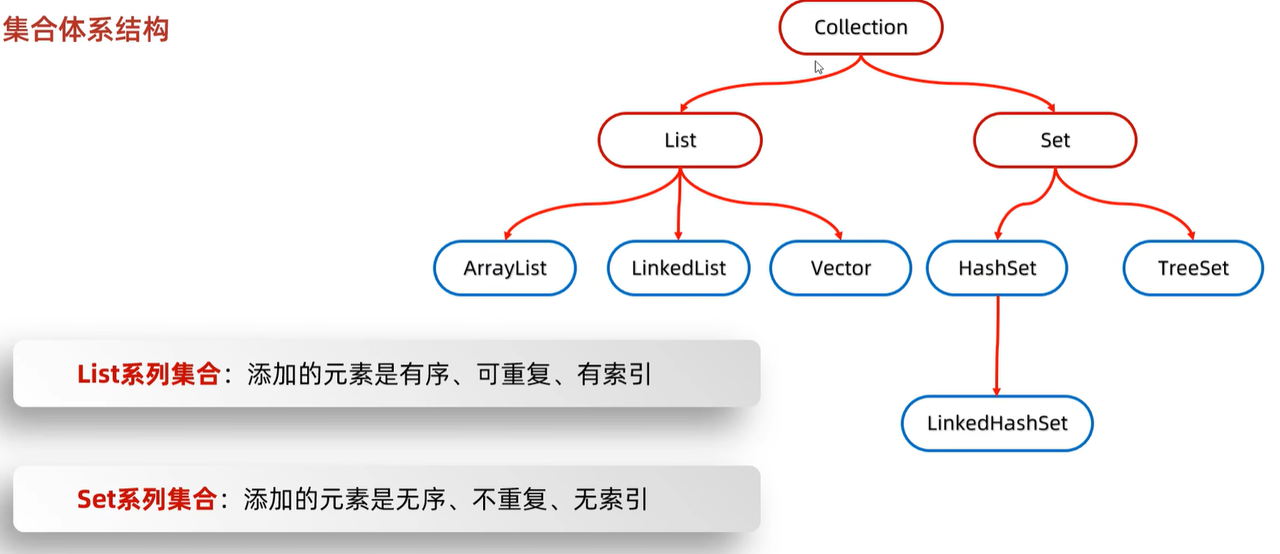
collection和map分别为单列集合的祖宗和双列集合(一次性插入)的祖宗。list和set通过实现collection使用。
collection
1. 数据结构
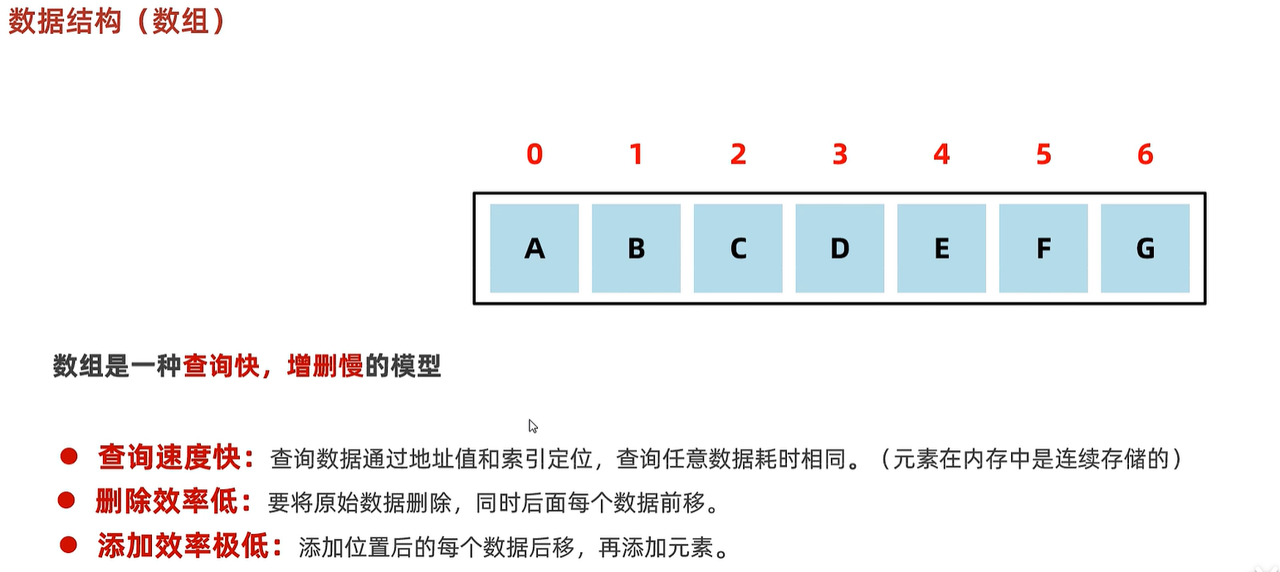
数组:连续的地址空间,通过下标快速查找,删除和添加需要移动数组元素所以慢。
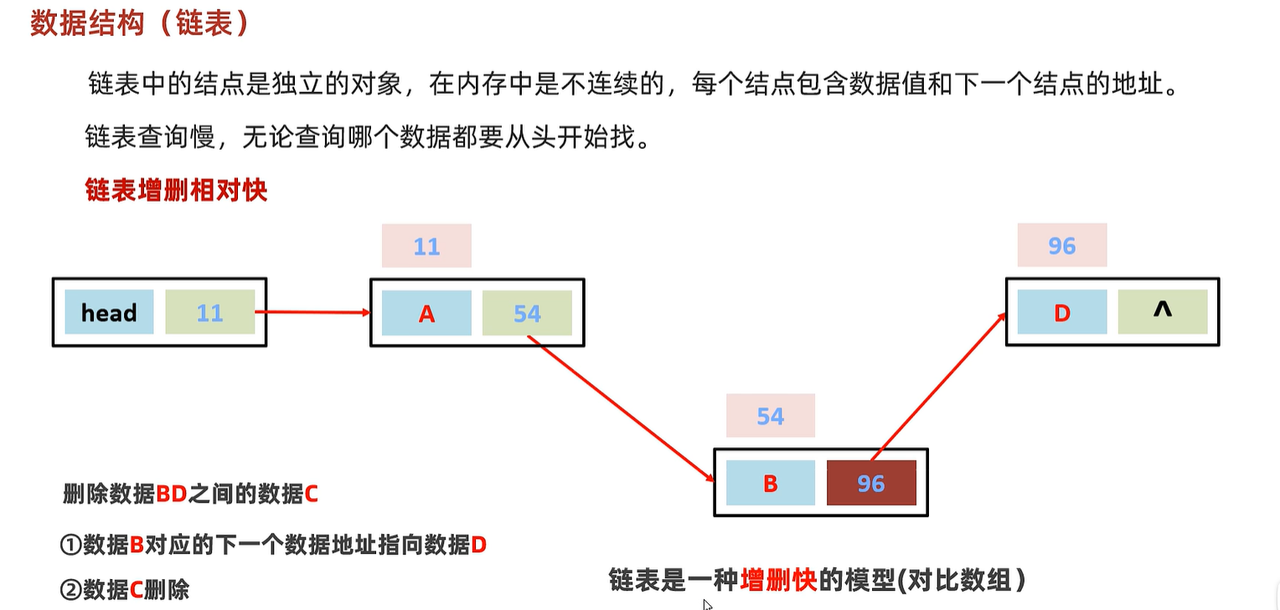
链表:不连续的地址空间,通过指针指向前一个和后一个。删除和插入只需要通过去掉指针和移动指针指向即可。查询比较慢因为每次查询都需要从头开始遍历。
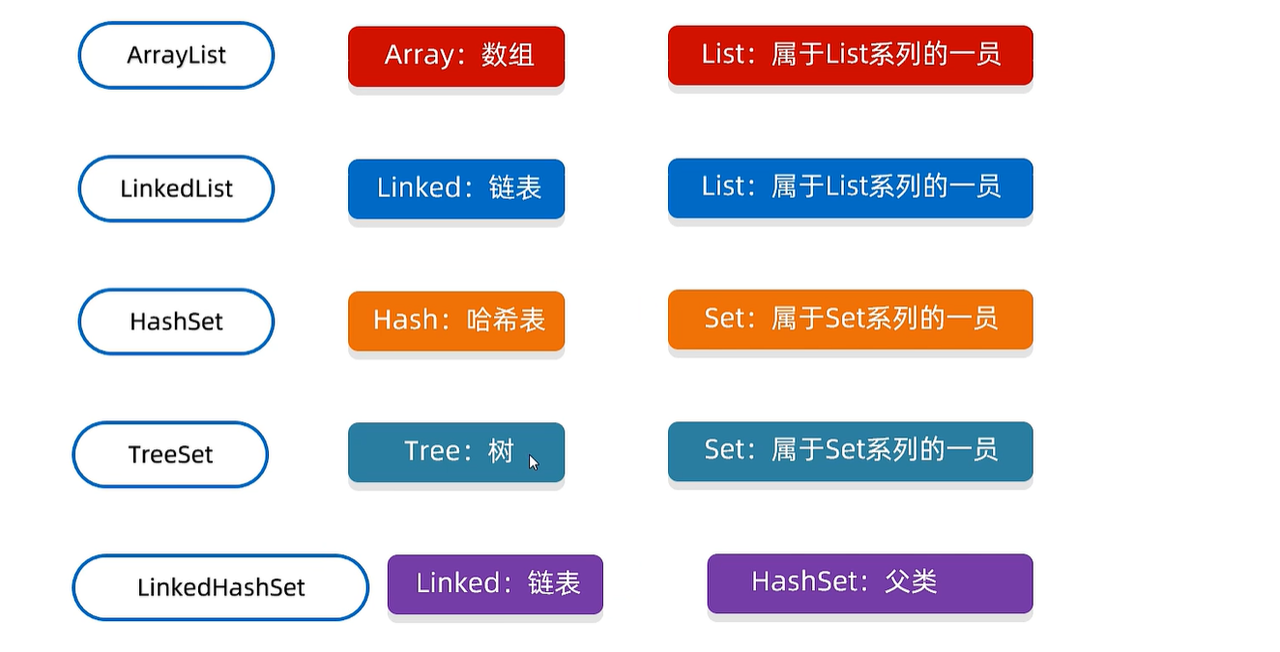
- 集合看名字知道数据结构并了解数据结构特点。
树:一个节点之间不仅仅存储值,还存储左右父节点地址(父左右节点存在时)
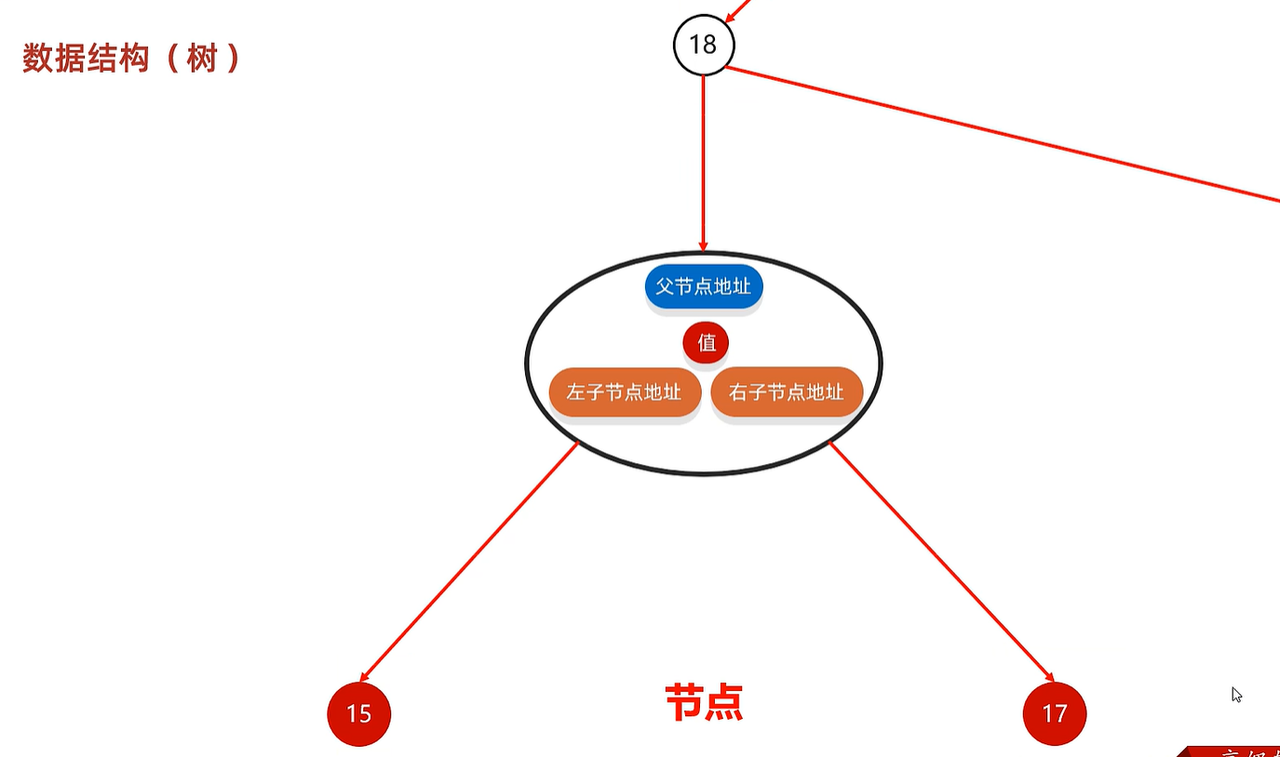
小结:

1. 什么是二叉树?
- 一种存储数据的数据结构,特点是每个节点最多两个子节点。每个节点的值是无规律的。
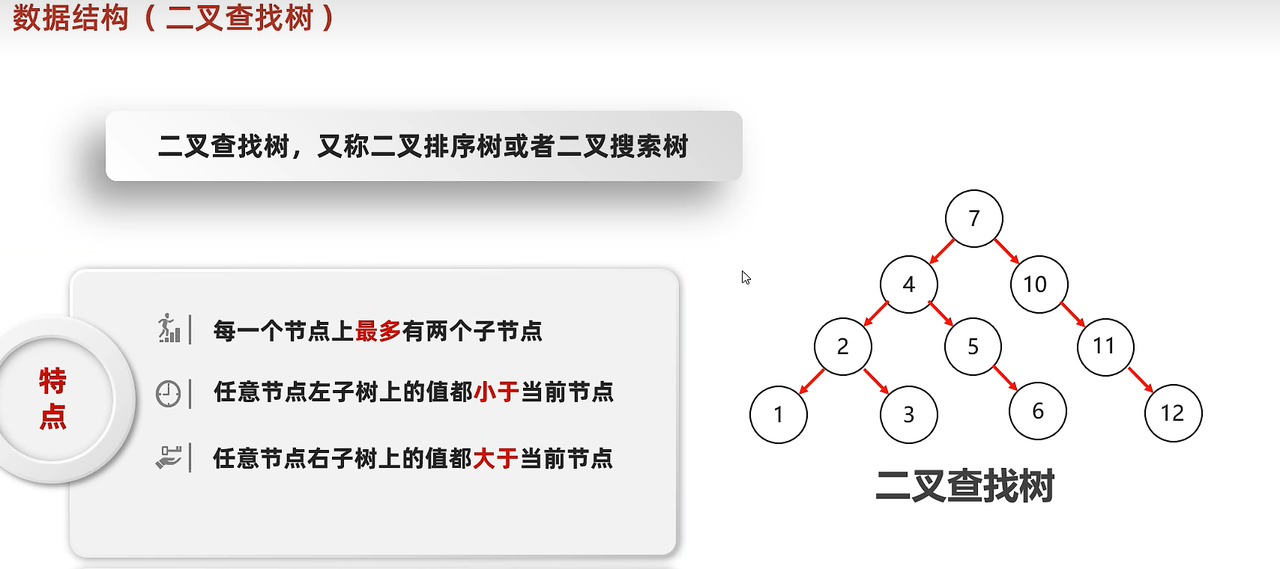
2. 二叉查找树?
- 特点是:最多两个子节点。任何节点的左子节点比该节点小,任何右子节点比此节点大。
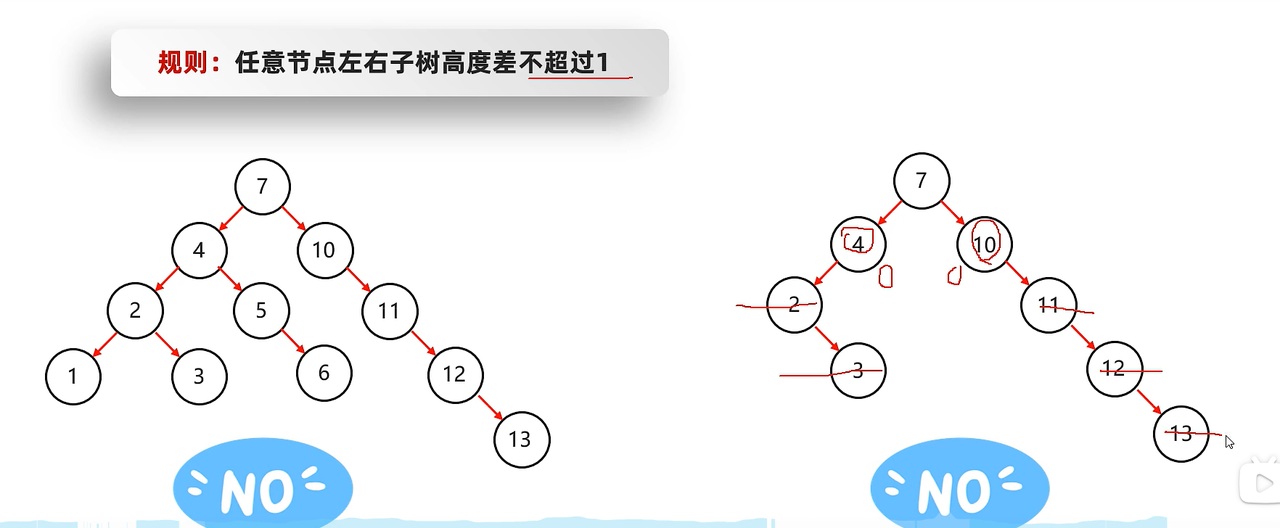
3. 什么是平衡二叉树?
- 任意节点左右子树的高度差不超过1。
- 如何保证平衡的?
- 通过旋转机制达到平衡。
- 类别包含左旋和右旋。
- 旋转触发是由插入新数据时,破坏了平衡就会旋转。
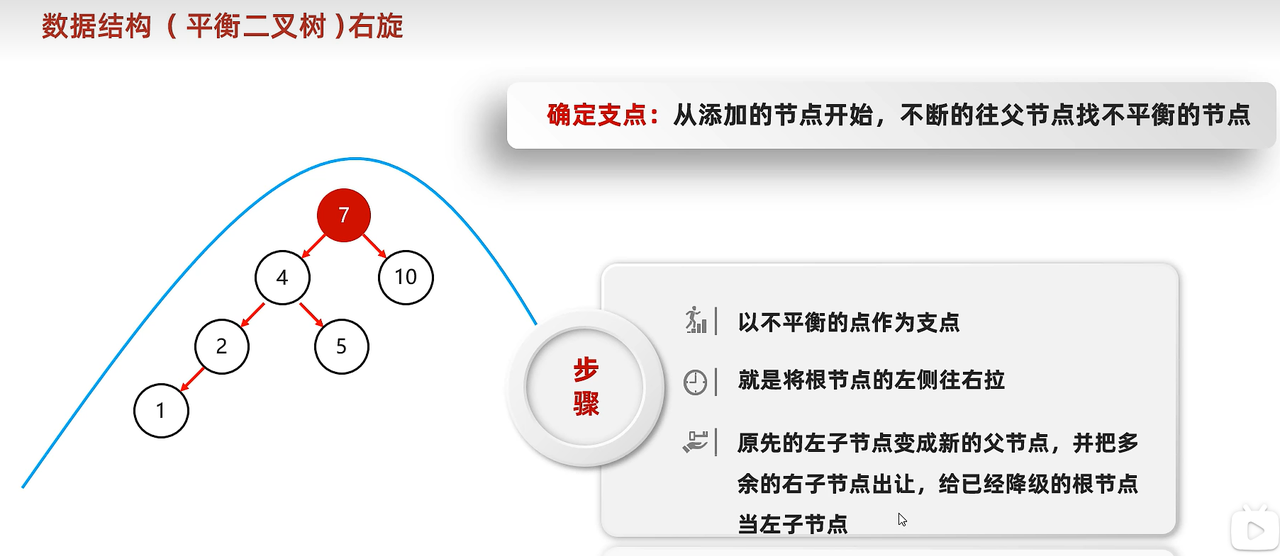
- 如何旋转?
- 左旋:图一为简单的左旋结构,需要旋转的根节点上无多余的节点。

- 较为复杂的左旋:需要将9这个节点作为降级的根节点7的右子节点。
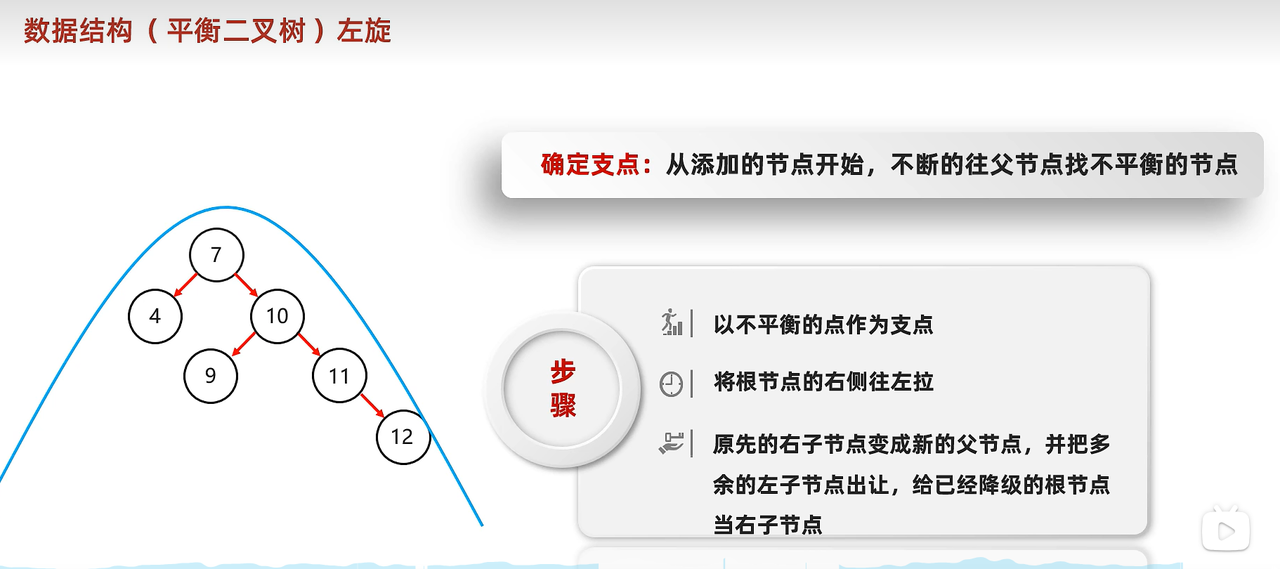
- 较为复杂的左旋:需要将9这个节点作为降级的根节点7的右子节点。
- 右旋:同理简单和复杂的类似左旋
- 左旋:图一为简单的左旋结构,需要旋转的根节点上无多余的节点。
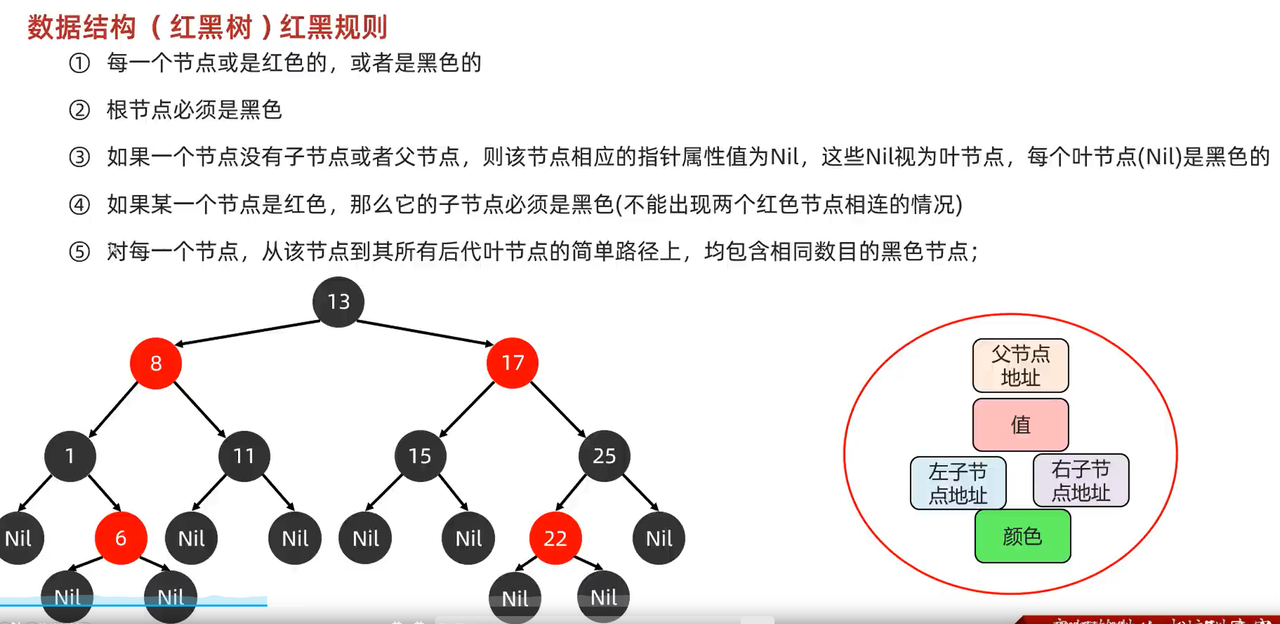
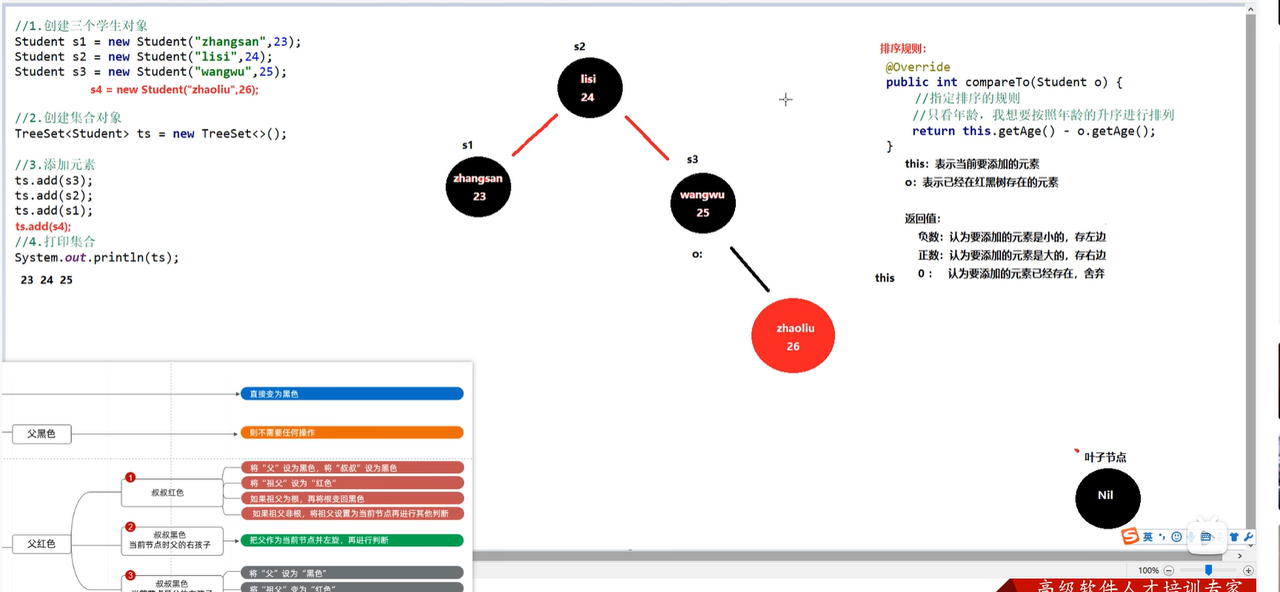
- 红黑树
- 由于平衡二叉树每次节点的左右节点高度差超过1就要自旋调整。所以引入红黑树。红黑树不是高度平衡的,通过红黑规则进行实现。
- 红黑树增删查改效率都很高。
- 红黑树增加节点的时候,默认是红色的。因为红色效率高,调整红黑颜色次数较少。
2. list 有序可重复有索引
ArrayList数据结构和扩容机制
- 底层是数组结构,初始化长度为0,当插入第一个数据的时候默长度为10,满之后扩展到1.5倍。当一次插入多个则以实际长度扩容。

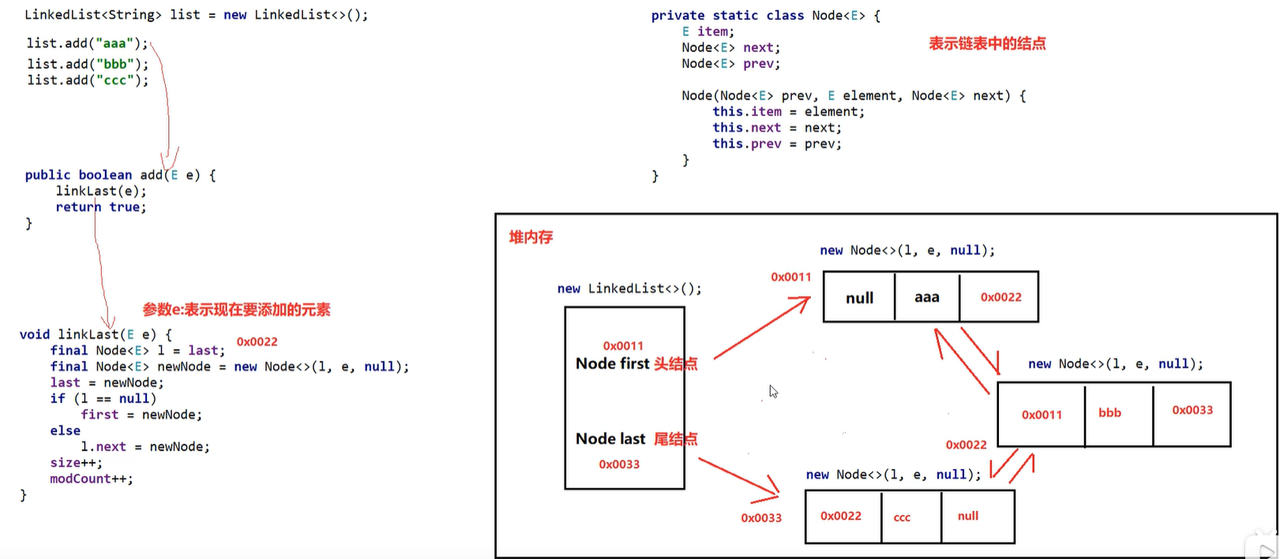
LinKedList数据接口和扩容机制
- 底层是双向链表 头节点数据和尾节点。
- add数据过程为:重点是头节点和尾节点,每次记录上个节点的地址记录到下一个地址的头部。
CopyOnWriteArrayList
- CopyOnWriteArrayList是什么?
- 相当于线程安全的arrayList
- 实现原理?
- 当写入数据时,先拷贝一份数组,然后对新数组进行操作,之后将引用指向新数组,注意add操作期间都是加锁的(sysnconized),所以能保证线程安全。这样做的好处是并发读取时不会加锁,提高读取效率。所以适合读多写少的场景。
- 缺点就是:复制数组开销大。
3. set
hashSet 无序不可重复
- 元素是唯一的,重复添加数据时,会返回false

- 由于set和list都是继承collection,所以增删改查方法基本一样哦。
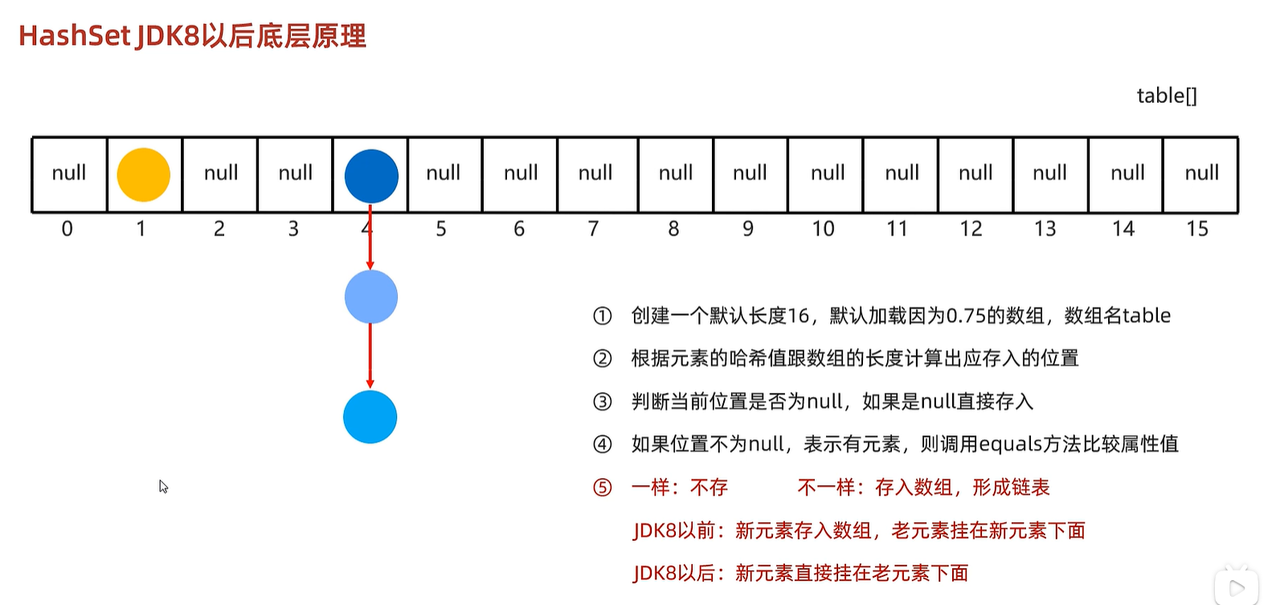
- hashSet底层是通过哈希表实现的。
- 哈希表由jdk8之前由数组+链表组成,jdk8之后由数组+链表+红黑树组成。
- 什么是hashcode?hashcode是对象的整数值表达式
- hashcode默认是根据 对象.hashcode() 方法计算出的。本质是对象的内存地址经过转换的出的整数值。

- hashcode默认是根据 对象.hashcode() 方法计算出的。本质是对象的内存地址经过转换的出的整数值。
- 当链表长度大于8且数组长度大于等于64的时候,链表就会转换为红黑树。
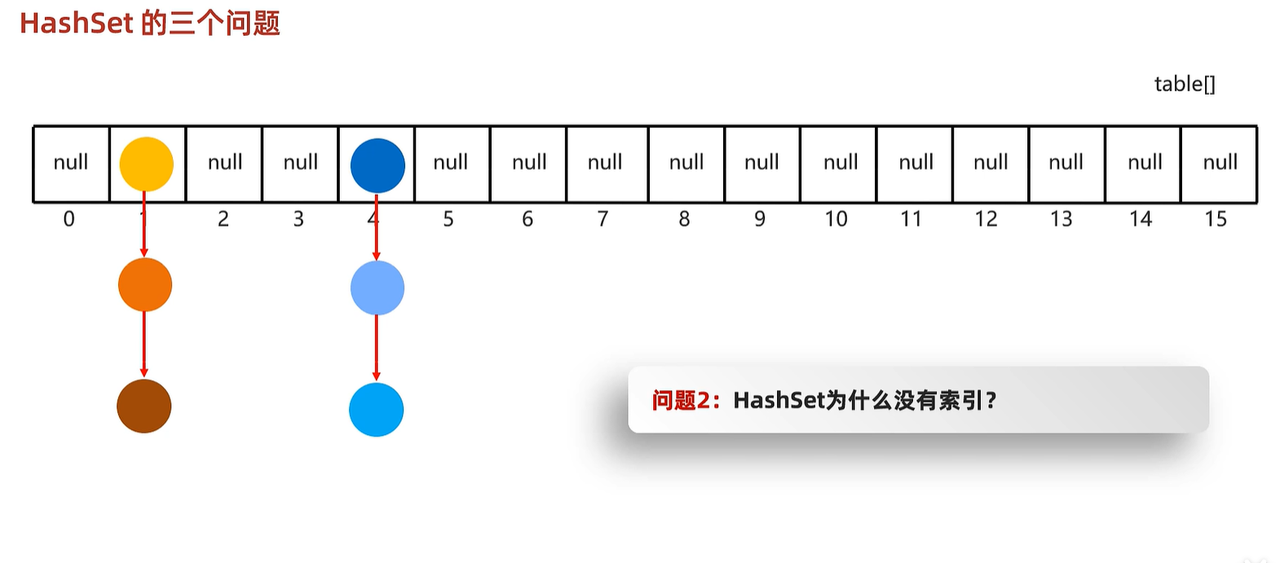
- 回答下列三个问题:
- 1.因为存的时候如果相同hashcode不同属性值的是存放在链表中,而取得话是根据依次或者数组和数组下的链表,所以顺序不一致。
- 2.数据结构多没有好的方式定义索引。
- 3.利用hashcode和equles方法比较。

treeSet 可排序 不可重复
- 底层是基于红黑树实现的
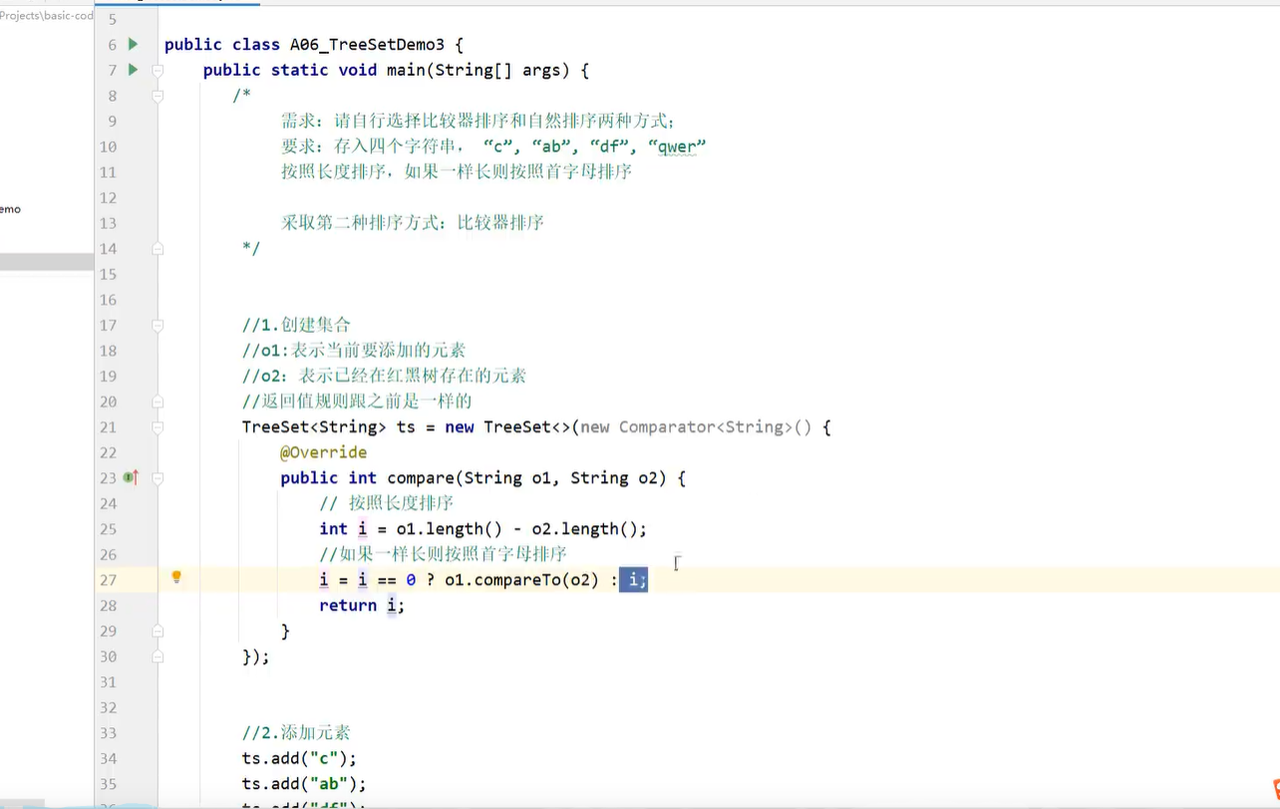
- 可排序:如果是基本类型则输出set后会按照数字大小升序排列(1,2,3,4),如果是引用类型则按照ascii进行排序输出(a,b,c,d)
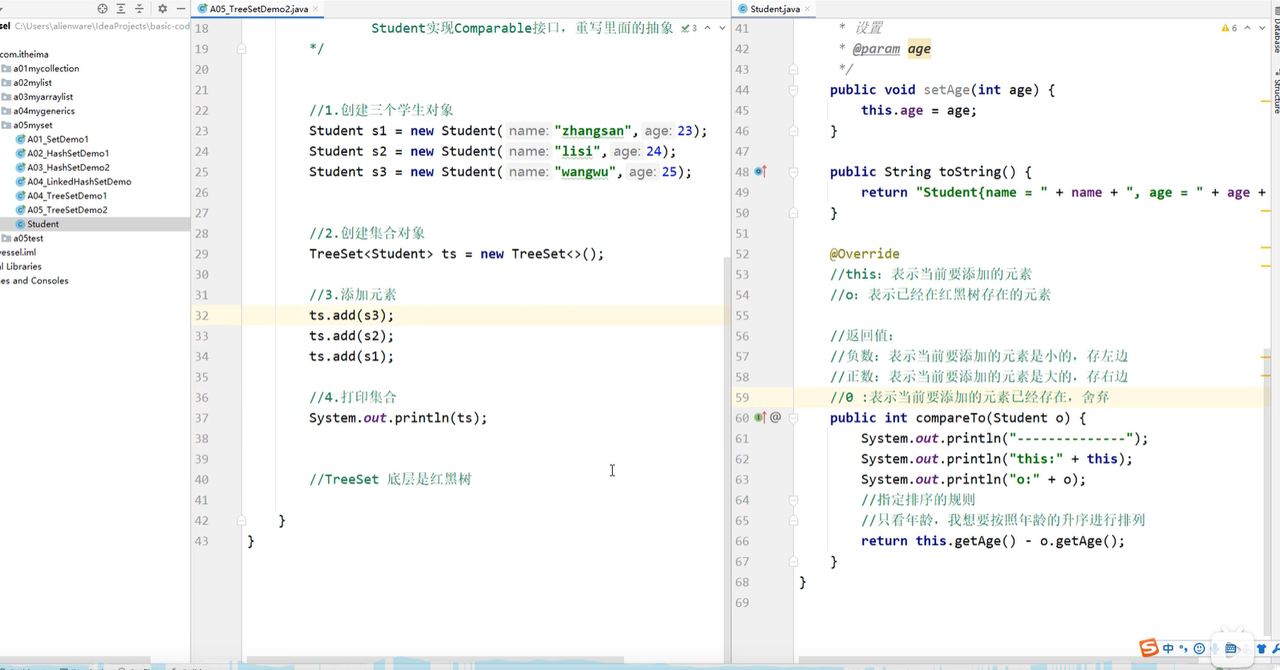
- 默认使用treeset需要实现comprable接口,重写里面的compareTo方法指定字段继续比较排序。
- treeset实现比较的方式有两种:
- 实现comprable接口,重写里面的compareTo方法
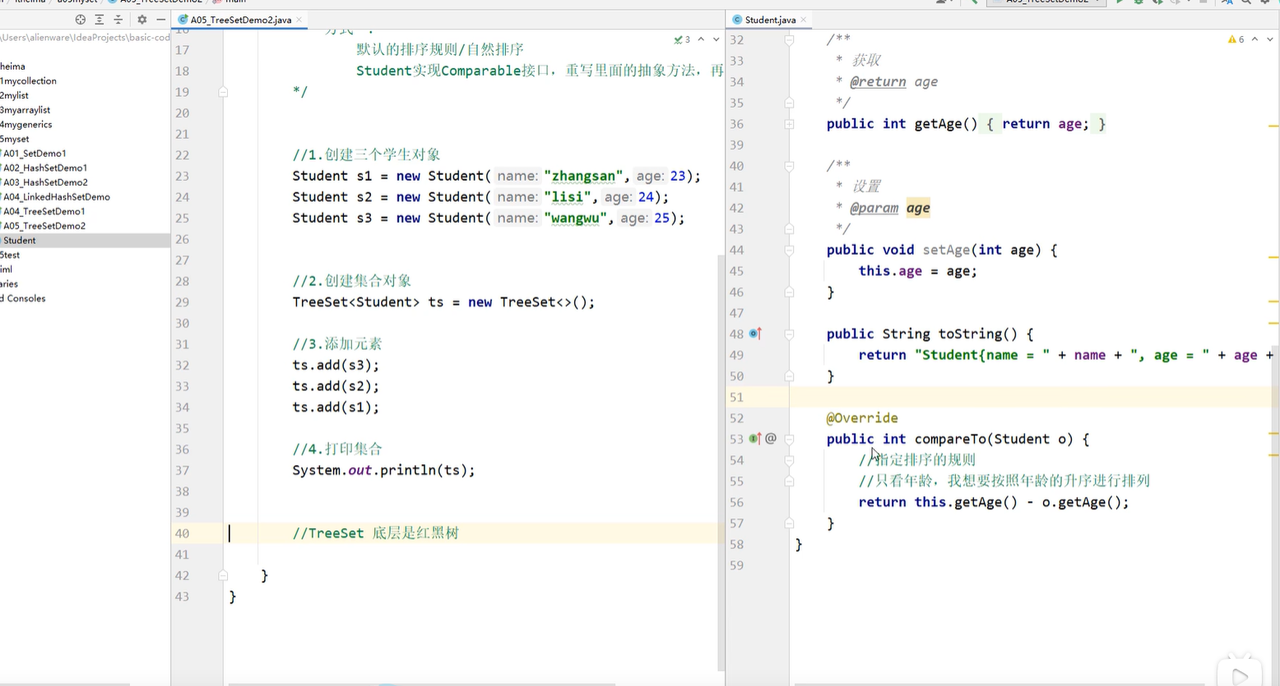
- New comparator()重写里面的compare方法,先进行字段排序,之后在调用compareto方法比较。

- 实现comprable接口,重写里面的compareTo方法
- treeset实现比较的方式有两种:
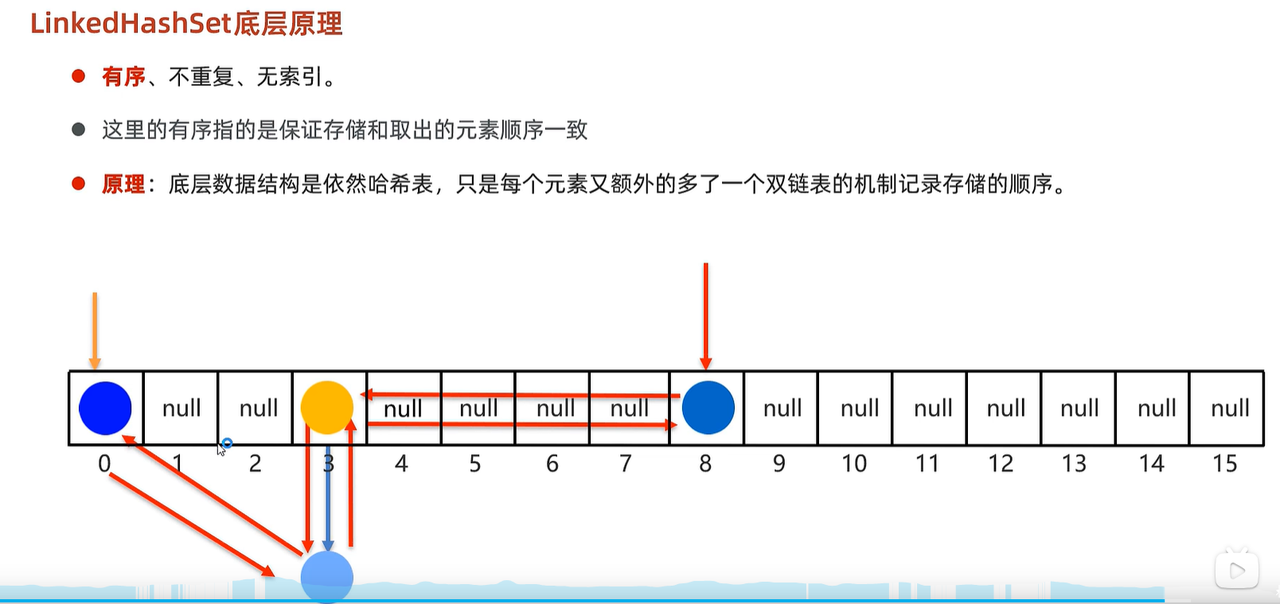
linkedHashSet 有序不可重复
- 1.底层数据结果依旧是哈希表,不同的是多了一个双向链表用来记录存入的元素顺序。
- 2.读取数据的时候就不再是按照数组下标遍历了,而是遍历双向链表依次获取元素。
ConcurrentHashMap 线程安全
如何实现的呢?
- jdk1.7之前采用分段锁,使用ReentrantLock实现。jdk1.8之后采用cas+synchronized锁桶下标。
重写hashcode和equals方法
- 重写的目的是将hashcode默认的地址转换的整数值变成由对象属性值相同hashcode就相同。
- 比较的是对象的引用也就是地址值是否相等。equals一般跟都是比较地址值,但大多数都会重写equals方法比较属性值。
4. map
hashmap 集合&HashMap
- hashmap底层结构跟hashset是一样的都是哈希表。
- hashmap存储数据的过程:
- 1.跟value没关系!调用object的hashcode方法计算key的hashcode,然后取高低16位进行异或计算,在与数组进行&运算最后找到桶的位置。
- 2.然后比较桶中的key是否为空,空则存储。不为空则比较是否相等,相等则替换value值,不等则存储在链表中。(与hashset最大的区别在于hashset如果equals相同则不存,而hashmap多了一个value,所以会替换相同key 的value值)

hash冲突?
- 什么是hash冲突?
- 不同对象计算出的hashcode值相同,存储在同一个桶位置时就会冲突。
- hash解决冲突的方式?
- 1.拉链法 hashmap采用的方式 也就是相同hashcode不同属性值通过尾插法保存到链表上。jdk8之前使用头插法
- 2.再hash法 如果冲突则还另一种hash算法计算
- 3.开放定址法 冲突时找一个空闲的数组进行存储即可。
- hashmap采用的方式 拉链法
- hashmap的线程安全?
- 线程不安全,可以使用ConcurrentHashMap实现高并发的场景
hashmap的扩容?
- hashmap的扩容机制:初始化数组长度时16,负载因子7.5 当存储的数据达到12时进行扩容两倍。当链表长度达到8且数组长度64时链表转换为红黑树。如果继续扩容当链表小于6时又会转换为链表。
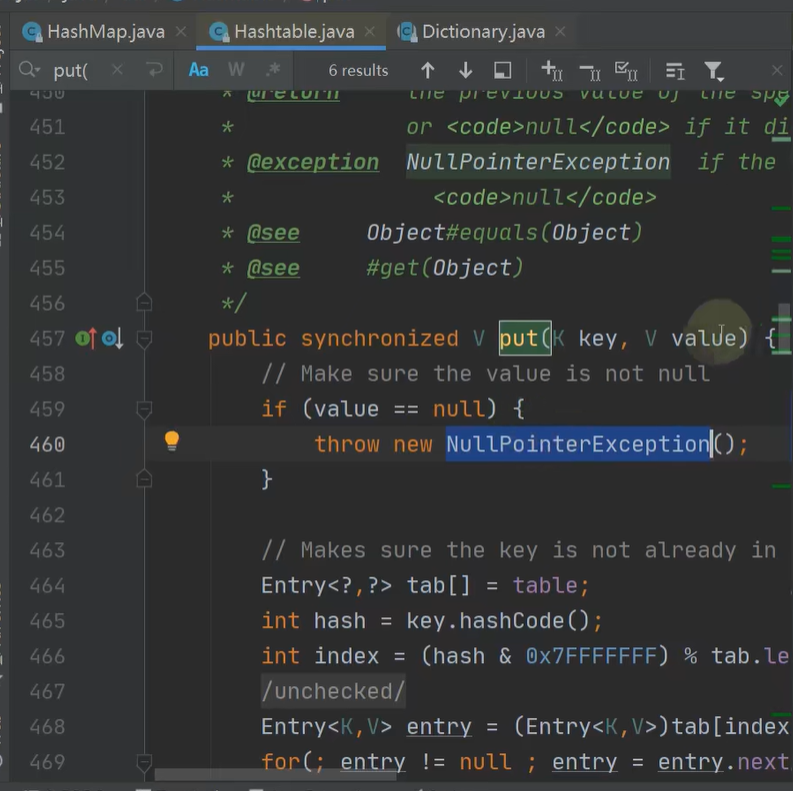
Hashtable 线程安全
- 底层都是数组加链表 注意初始值长度为11 每次扩容为2倍加1
- 为什么线程安全,因为hashtable的所有方法都加了synchronized,所有线程调用方法都要依次排队。
- hashtable的key和value是不能为空的,否则报空指针。
面试常问
自测题:1. java集合自测题(高阶源码版)
2. https://www.yuque.com/hollis666/wty0im/gxi0rc
1. 线程安全的集合有哪些?concurrentHashMap hashtable copyOnWriteArrayList
2. 了解过fail-fast和fail-safe吗? 待理解
3. 除了自带的线程安全集合,如何将集合变成线程安全的呢?
- 1.使用synchronized或者ReentrantLock对代码加锁(读写都要加锁)

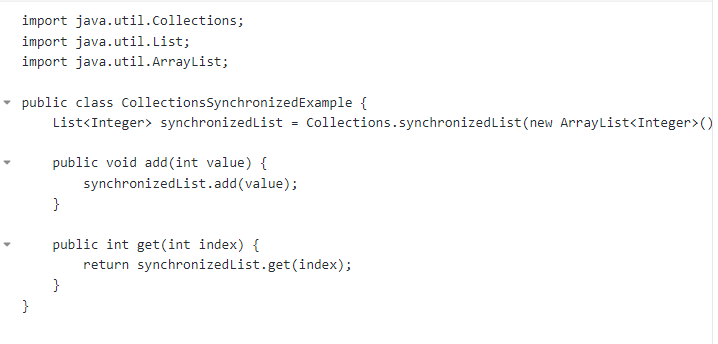
- 2.使用Collections.synchronizedList/map(new arrayList<>/new hashMap())获取线程安全的集合。
4. hashmap中为什么长度达到8才转红黑树呢?
- 1.如果使用红黑树替换链表,是因为红黑树的空间大小是链表的两倍,比较浪费空间。
- 2.前提是红黑树的查询速度是比链表快的,但是插入数据上效率要慢得多。所以当hash冲突导致链表长度到达8时(达到8的概率极低统计学计算得出)使用红黑树兜底提供查询效率。
- 3.为什么是6是转换为链表,而不是小于8就转。防止频繁在链表和红黑树之间的转换。
评论区